Beam reads your data from a diverse set of supported sources, no matter if it’s on-prem or in the cloud.
Beam executes your business logic for both batch and streaming use cases.
Beam writes the results of your data processing logic to the most popular data sinks in the industry.
A simplified, single programming model for both batch and streaming use cases for every member of your data and application teams.
Apache Beam is extensible, with projects such as TensorFlow Extended and Apache Hop built on top of Apache Beam.
Execute pipelines on multiple execution environments (runners), providing flexibility and avoiding lock-in.
Open, community-based development and support to help evolve your application and meet the needs of your specific use cases.







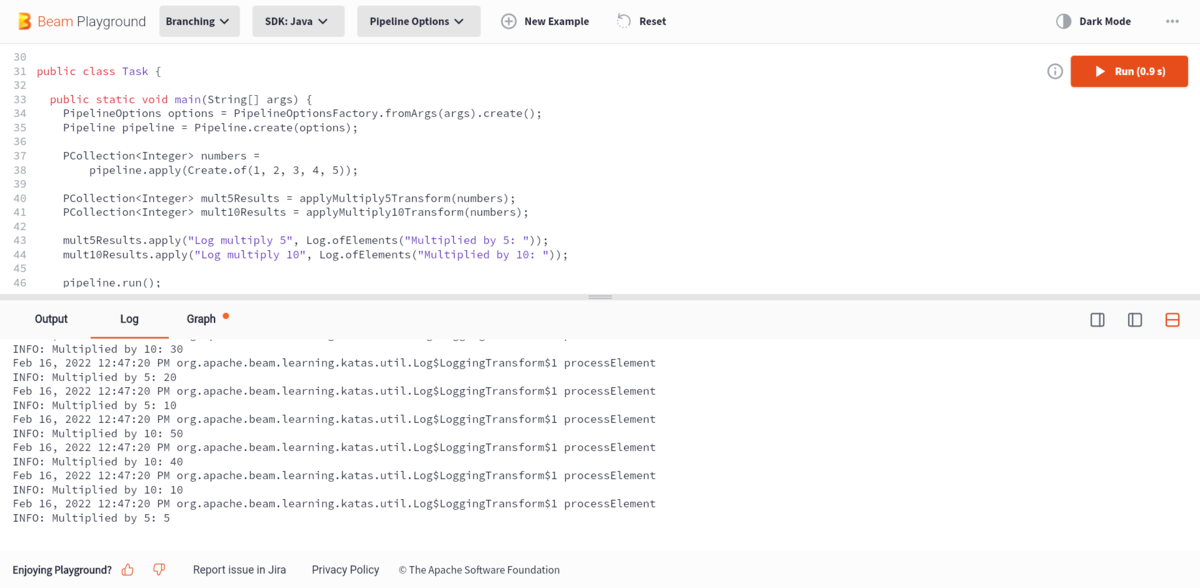
Beam Playground is an interactive environment to try out Beam transforms and examples without having to install Apache Beam in your environment. You can try the Apache Beam examples at Beam Playground.