



About
Why Apache Beam?
Apache Beam is an open-source, unified programming model for batch and streaming data processing pipelines that simplifies large-scale data processing dynamics. Thousands of organizations around the world choose Apache Beam due to its unique data processing features, proven scale, and powerful yet extensible capabilities.
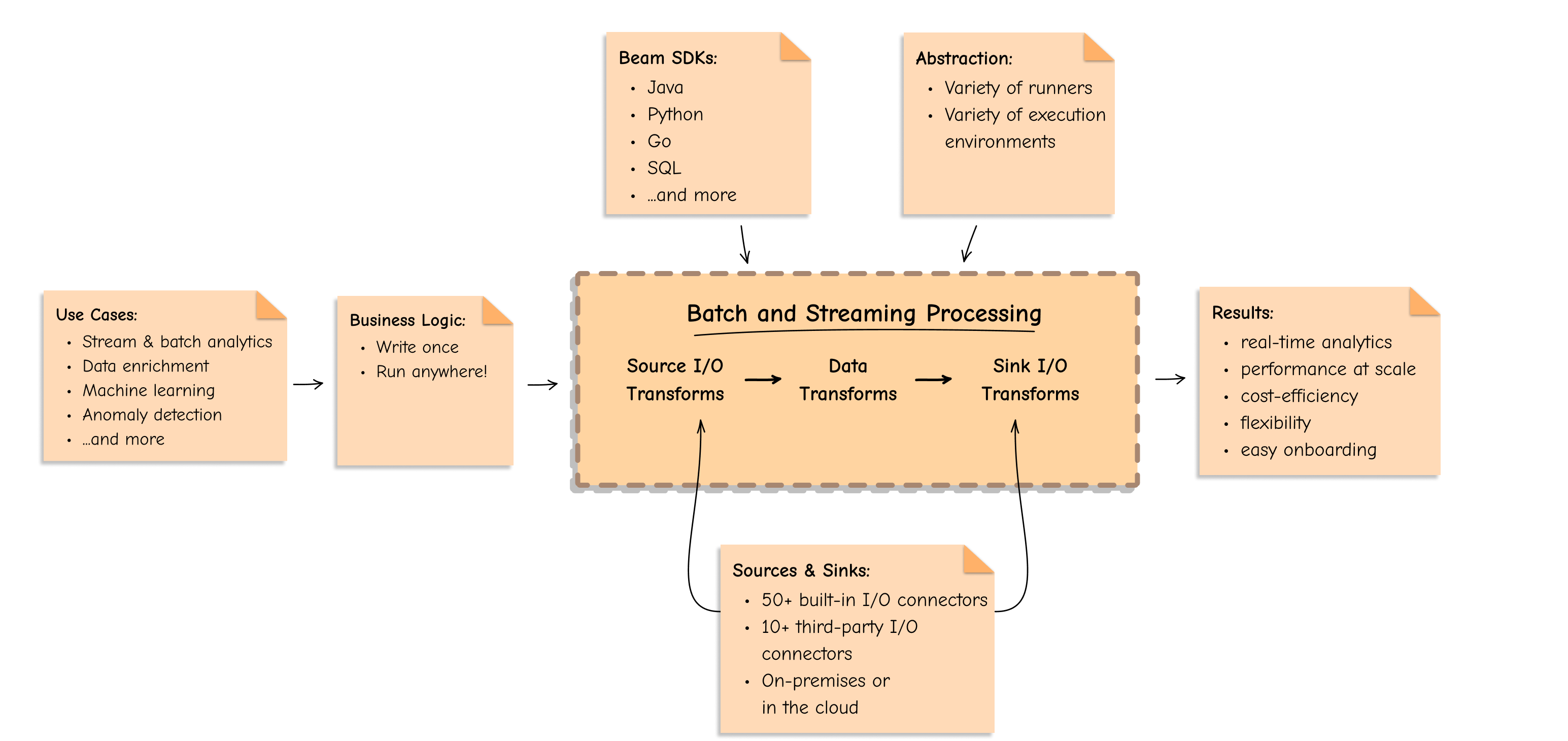
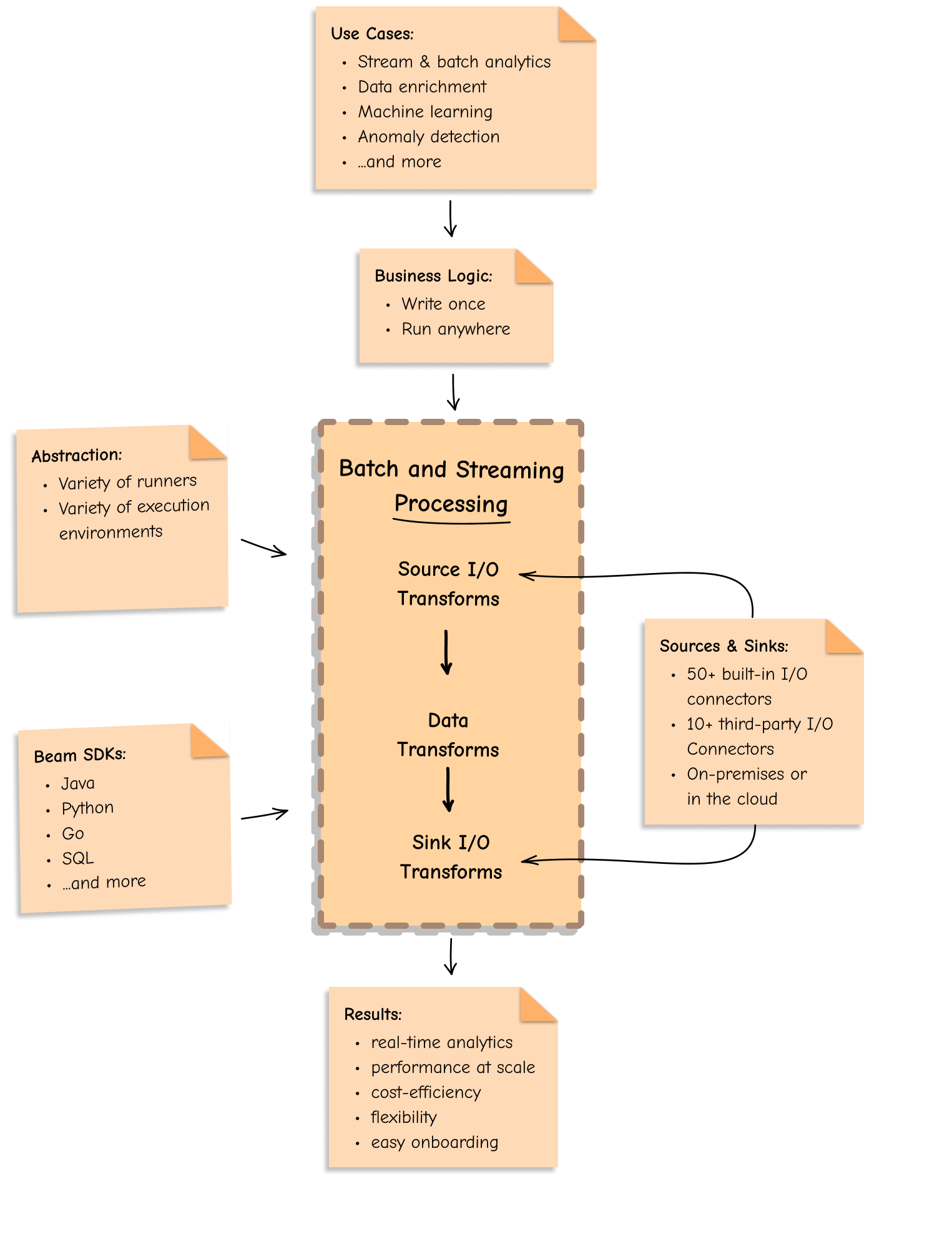
Apache Beam is the future of data processing because it provides:
Powerful Abstraction
The Apache Beam model offers powerful abstractions that insulate you from low-level details of distributed data processing, such as coordinating individual workers, reading from sources and writing to sinks, etc.
The pipeline abstraction encapsulates all the data and steps in your data processing task. You can think of your data processing tasks in terms of these abstractions.
The higher level abstractions neatly separate data from runtime characteristics and simplify the mechanics of large-scale distributed data processing. You focus on creating value for customers and business while the Dataflow model handles the rest.
Unified Batch and Streaming Programming Model
Apache Beam provides flexibility to express the business logic just once and execute it for both batch and streaming data pipelines, on-premises via OSS runners or in the cloud via managed services such as Google Cloud Dataflow or AWS Kinesis Data Analytics.
Apache Beam unifies multiple data processing engines and SDKs around its distinctive Beam model. This offers a way to easily create a large-scale common data infrastructure across different applications that consume the data.
Cross-language Capabilities
You can select a programming language from a variety of language SDKs: Java, Python, Go, SQL, TypeScript, Scala (via Scio), or leverage multi-language capabilities to empower every team member to write transforms in their favorite programming language and use them together in one robust, multi-language pipeline. Apache Beam eliminates the skill set dependency and helps avoid becoming tied to a specific technology skill set and stack.
Portability
Apache Beam provides freedom to choose between various execution engines, easily switch between a variety of runners, and remain vendor-independent. Apache Beam is built to “write once, run anywhere”, and you can write data pipelines that are portable across languages and runtime environments, both open-source (e.g. Apache Flink and Spark) and proprietary (e.g. Google Cloud Dataflow and AWS KDA).
Extensibility
Apache Beam is open source and extensible. Multiple projects, such as TensorFlow Extended and Apache Hop, are built on top of Apache Beam and leverage its ability to “write once, run anywhere”.
New and emerging products expand the number of use cases and create additional value-adds for Apache Beam users.
Flexibility
Apache Beam is easy to adopt and implement because it abstracts you from low-level details and provides freedom of choice between programming languages.
The Apache Beam data pipelines are expressed with generic transforms, thus they are understandable and maintainable, which helps accelerate Apache Beam adoption and onboarding of new team members.
Apache Beam users report that they experience impressive time-to-value. Most notably, they noted a reduction in the time needed to develop and deploy a pipeline, going down from several days to just a few hours.
Ease of Adoption
Apache Beam is easy to adopt and implement because it abstracts you from low-level details and provides freedom of choice between programming languages.
The Apache Beam data pipelines are expressed with generic transforms, thus they are understandable and maintainable, which helps accelerate Apache Beam adoption and onboarding of new team members. Apache Beam users report that they experience impressive time-to-value.
Most notably, they noted a reduction in the time needed to develop and deploy a pipeline, going down from several days to just a few hours.
Learn more about how Apache Beam enables custom use cases and orchestrates complex business logic for Big Data ecosystems of frontrunners in various industries by diving into our Case Studies section.
About Apache Beam Project
Apache Beam is a top-level project at Apache - the world’s largest, most welcoming open source community. Data processing leaders around the world contribute to Apache Beam’s development and make an impact by bringing next-gen distributed data processing and advanced technology solutions into reality.
Apache Beam was founded in early 2016 when Google and other partners (contributors on Cloud Dataflow) made the decision to move the Google Cloud Dataflow SDKs and runners to the Apache Beam Incubator.
Apache Beam was released in 2016 and has become a readily available and well-defined unified programming model that can express business logic in batch and streaming pipelines and allow for a unified engine-independent execution.
The vision behind Apache Beam is to allow developers to easily express data pipelines based on the Beam model (=Dataflow model) and to have a freedom of choice between engines and programming languages.
The Apache Beam unified programming model is evolving very fast, continuously expanding the number of use cases, runners, language SDKs, and built-in and custom pluggable I/O transforms that it supports.
Last updated on 2026/06/04
Have you found everything you were looking for?
Was it all useful and clear? Is there anything that you would like to change? Let us know!