



blog
2023/12/18
Build a scalable, self-managed streaming infrastructure with Beam and Flink: Tackling Autoscaling Challenges - Part 2Talat Uyarer
Build a scalable, self-managed streaming infrastructure with Flink: Tackling Autoscaling Challenges - Part 2
Welcome to Part 2 of our in-depth series about building and managing a service for Apache Beam Flink on Kubernetes. In this segment, we’re taking a closer look at the hurdles we encountered while implementing autoscaling. These challenges weren’t just roadblocks. They were opportunities for us to innovate and enhance our system. Let’s break down these issues, understand their context, and explore the solutions we developed.
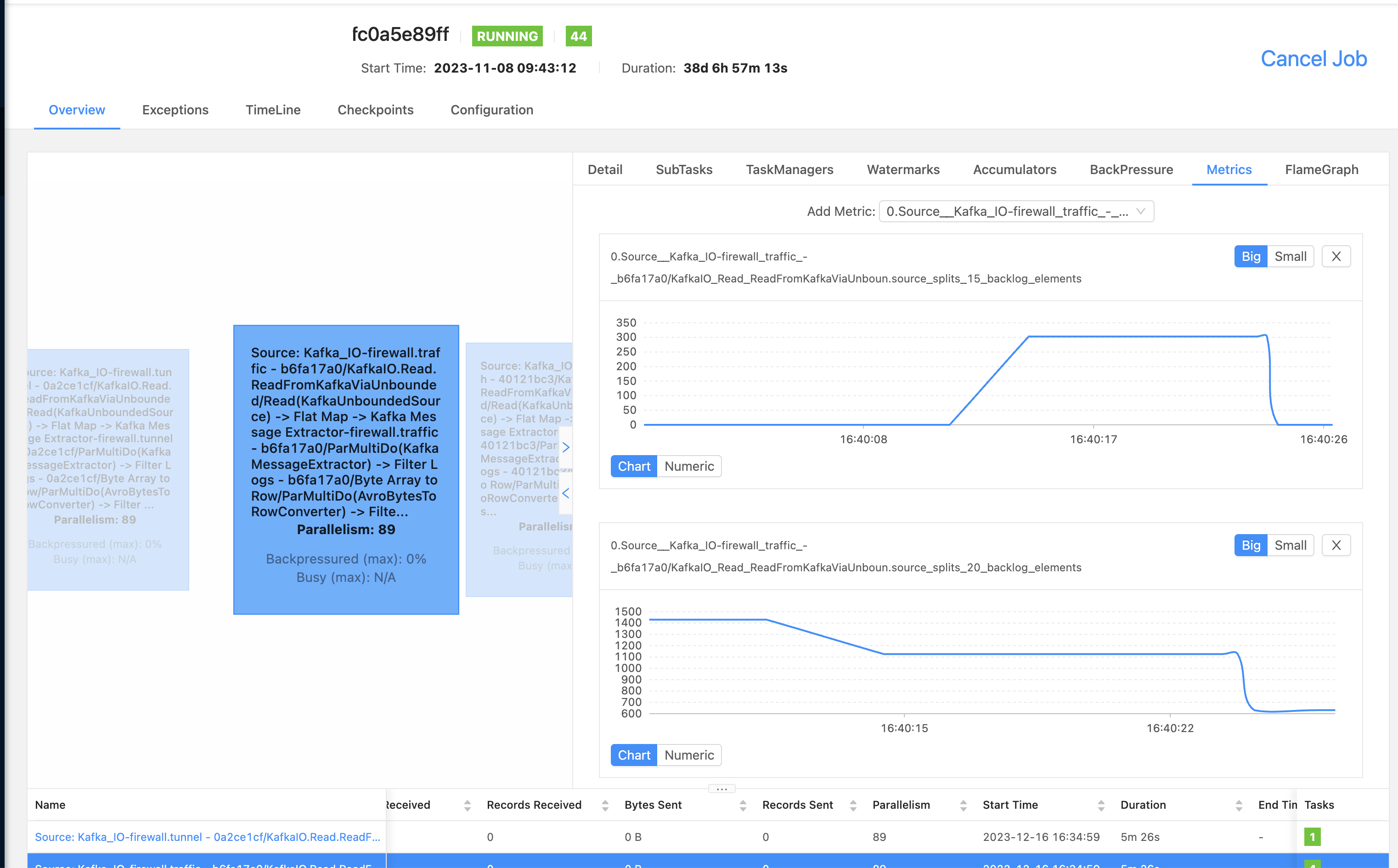
Understand Apache Beam backlog metrics in the Flink runner environment
The Challenge: In our current setup, we are using Apache Flink for processing data streams. However, we’ve encountered a puzzling issue: our Flink job isn’t showing the backlog metrics from Apache Beam. These metrics are critical for understanding the state and performance of our data pipelines.
What We Found: Interestingly, we noticed that the metrics are actually being generated in KafkaIO, which is a part of our data pipeline that handles Kafka streams. But when we try to monitor these metrics through the Apache Flink Metric system, we can’t find them. We suspected that there might be an issue with the integration (or ‘wiring’) between Apache Beam and Apache Flink.
Digging Deeper: On closer inspection, we found that the metrics should be emitted during the ‘Checkpointing’ phase of the data stream processing. During this crucial step, the system takes a snapshot of the stream’s state, and the metrics are typically metrics that are generated for unbounded sources. Unbounded sources are sources that continuously stream data, like Kafka.
A Potential Solution: We believe the root of the problem lies in how the metric context is set during the checkpointing phase. A disconnect appears to prevent the Beam metrics from being properly captured in the Flink Metric system. We proposed a fix for this issue, which you can review and contribute to on our GitHub pull request: Apache Beam PR #29793.
Overcoming challenges in checkpoint size reduction for autoscaling Beam jobs
In this section we will discuss strategies for reducing the size of checkpoints in autoscaling Apache Beam jobs, focusing on efficient checkpointing in Apache Flink and optimizing bundle sizes and PipelineOptions to manage frequent checkpoint timeouts and large-scale job requirements.
Understand the basics of checkpointing in Apache Flink
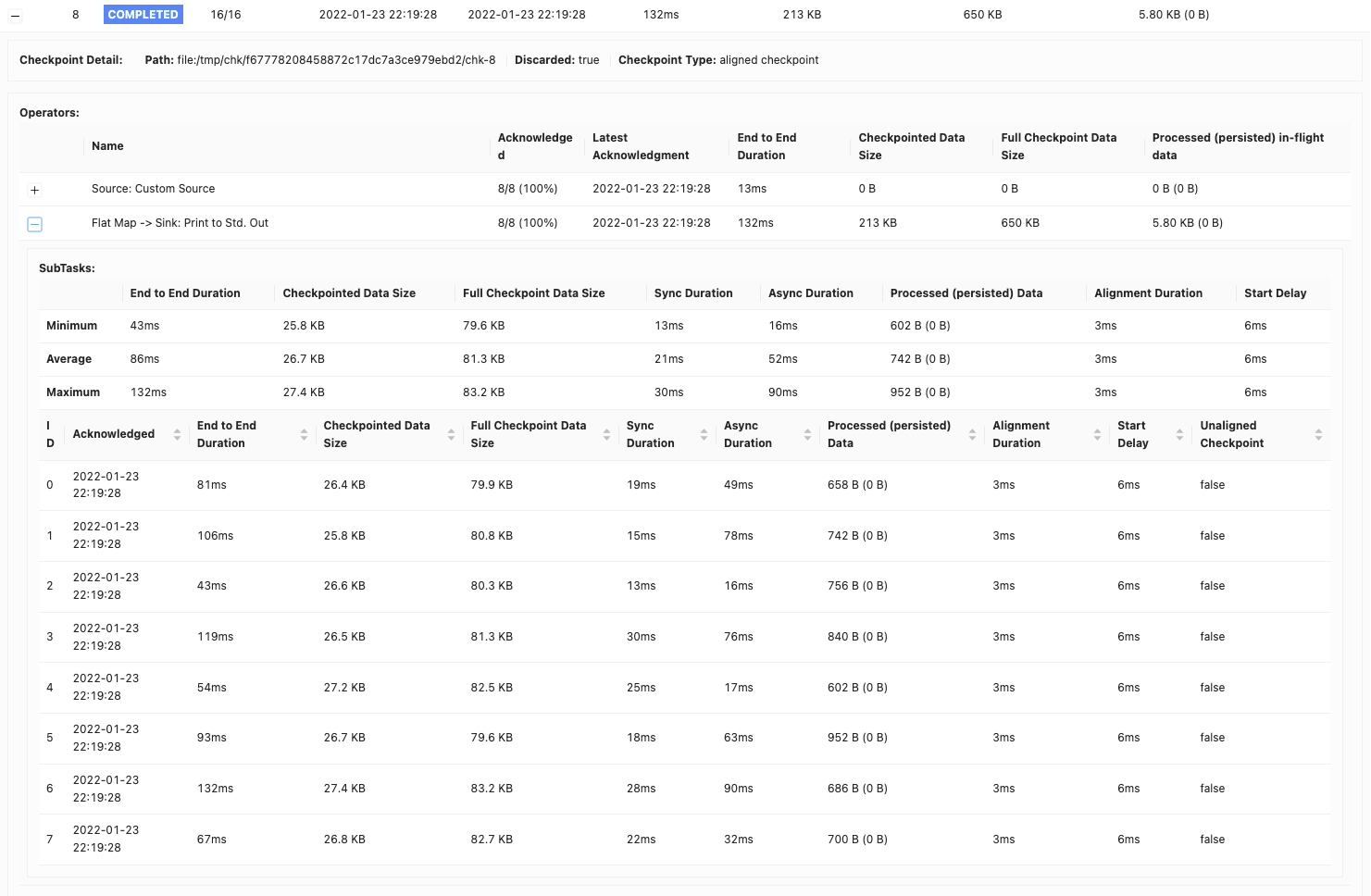
In stream processing, maintaining state consistency and fault tolerance is crucial. Apache Flink achieves this through a process called checkpointing. Checkpointing periodically captures the state of a job’s operators and stores it in a stable storage location, like Google Cloud Storage or AWS S3. Specifically, Flink checkpoints a job every ten seconds and allows up to one minute for this process to complete. This process is vital for ensuring that, in case of failures, the job can resume from the last checkpoint, providing exactly-once semantics and fault tolerance.
The role of bundles in Apache Beam
Apache Beam introduces the concept of a bundle. A bundle is essentially a group of elements that are processed together. This step enhances processing efficiency and throughput by reducing the overhead of handling each element separately. For more information, see Bundling and persistence. In the Flink runner default configuration, a bundle’s default size is 1000 elements with a one-second timeout. However, based on our performance tests, we adjusted the bundle size to 10,000 elements with a 10-second timeout.
Challenge: frequent checkpoint timeouts
When we configured checkpointing every 10 seconds, we faced frequent checkpoint timeouts, often exceeding 1 minute. This was due to the large size of the checkpoints.
Solution: Manage checkpoint size
In Apache Beam Flink jobs, the finishBundleBeforeCheckpointing option plays a pivotal role. When enabled, it ensures that all bundles are completely processed before initiating a checkpoint. This results in checkpoints that only contain the state post-bundle completion, significantly reducing checkpoint size. Initially, our checkpoints were around 2 MB per pipeline. With this change, they consistently dropped to 150 KB.
Address the checkpoint size in large-scale jobs
Despite reducing checkpoint sizes, a 150 KB checkpoint every ten seconds can still be substantial, especially in jobs that run multiple pipelines. For instance, with 100 pipelines in a single job, this size balloons to 15 MB per 10-second interval.
Further optimization: reduce checkpoint size with PipelineOptions
We discovered that due to a specific issue (BEAM-8577), our Flink runner was including our large PipelineOptions objects in every checkpoint. We solved this problem by removing unnecessary application-related options from PipelineOptions, further reducing the checkpoint size to a more manageable 10 KB per pipeline.
Kafka Reader wait time: solving autoscaling challenges in Beam jobs
Understand unaligned checkpointing
In our system, we use unaligned checkpointing to speed up the process of checkpointing, which is essential for ensuring data consistency in distributed systems. However, when we activated the finishBundleBeforeCheckpointing feature, we began facing checkpoint timeout issues and delays in checkpointing steps. Apache Beam leverages Apache Flink’s legacy source implementation for processing unbounded sources. In Flink, tasks are categorized into two types: source tasks and non-source tasks.
- Source tasks: fetch data from external systems into a Flink job
- Non-source tasks: process the incoming data
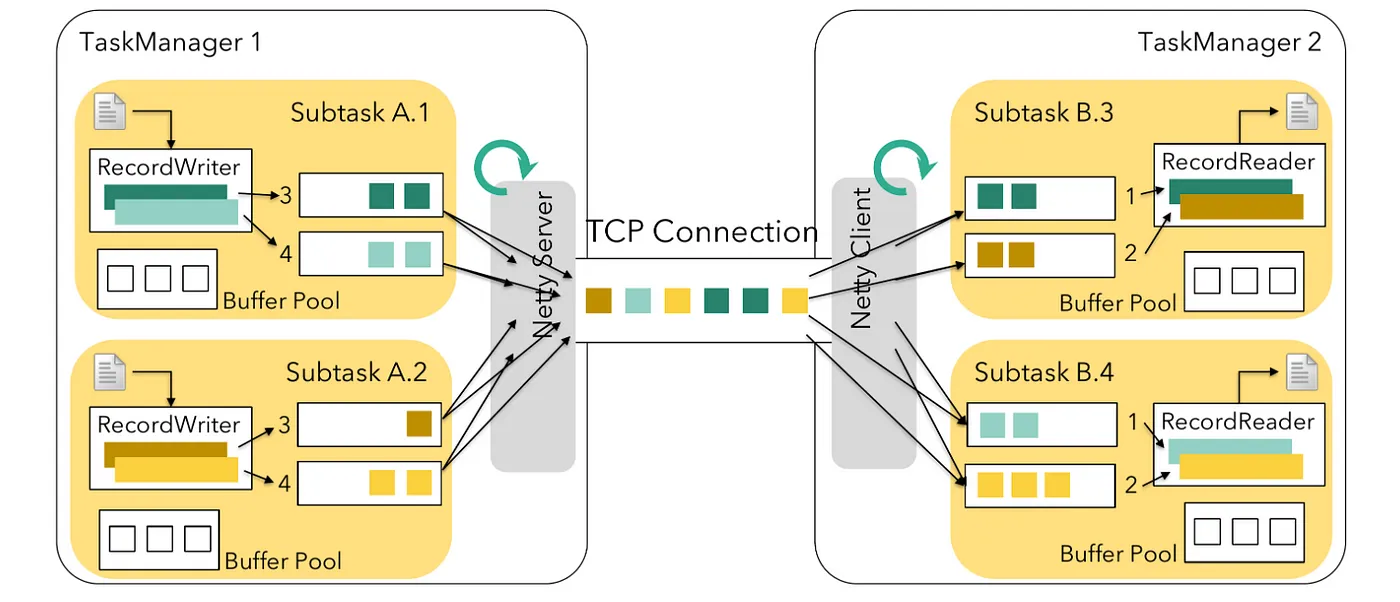
In the standard configuration, non-source tasks check for an available buffer before pulling data. If source tasks don’t perform this check, they might experience checkpointing delays in writing data to the output buffer. This delay affects the efficiency of unaligned checkpoints, which are only recognized by legacy source tasks when an output buffer is available.
Address the challenge with UnboundedSourceWrapper in Beam
To solve this problem, Apache Flink introduced a new source implementation that operates in a pull mode. In this mode, a task checks for a free buffer before fetching data, aligning with the approach of non-source tasks.
However, the legacy source, still used by Apache Beam’s Flink Runner, operates in a push mode. It sends data to downstream tasks immediately. This setup might create bottlenecks when buffers are full, causing delays in detecting unaligned checkpoint barriers.
Our solution
Despite its deprecation, Apache Beam’s Flink Runner still uses the legacy source implementation. To address its issues, we implemented our modifications and the quick workarounds suggested in FLINK-26759. These enhancements are detailed in our Pull Request. You can also find more information about unaligned checkpoint issues in the Flink Unaligned Checkpoint blog post.
Address slow reads in high-traffic scenarios
In our journey with Apache Beam and the Flink Runner, we encountered a significant challenge similar to one documented in the post How Intuit Debug Consumer Lags in Apache Beam by Antonio Si in his experience at Intuit. Their real-time data processing pipelines had increasing Kafka consumer lag, particularly with topics experiencing high message traffic. This issue was traced to Apache Beam’s handling of Kafka partitions through UnboundedSourceWrapper and KafkaUnboundedReader. Specifically, for topics with lower traffic, the processing thread paused unnecessarily, delaying the processing of high-traffic topics. We faced a parallel situation in our system, where the imbalance in processing speeds between high- and low-traffic topics led to inefficiencies.
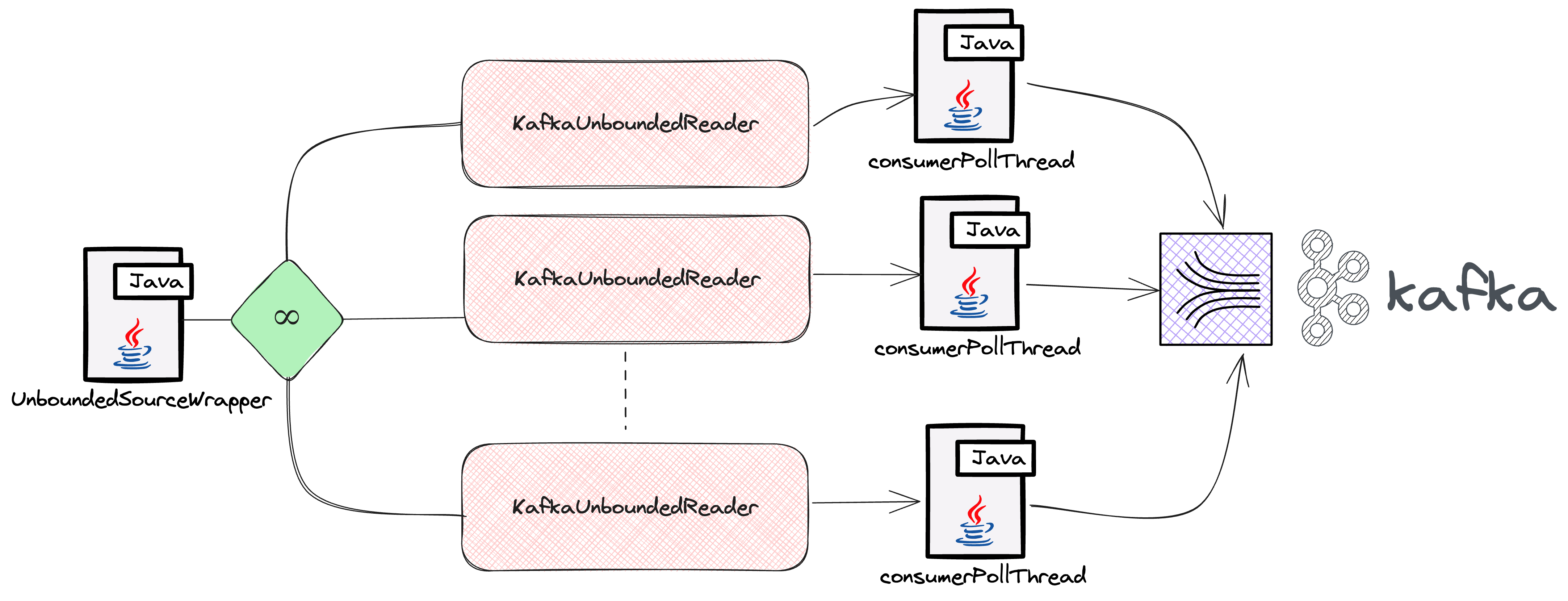
To resolve this issue, we developed an innovative solution: an adaptive timeout strategy in KafkaIO. This strategy dynamically adjusts the timeout duration based on the traffic of each topic. For low-traffic topics, it shortens the timeout, preventing unnecessary delays. For high-traffic topics, it extends the timeout, providing more processing opportunities. This approach is detailed in our recent pull request.
Unbalanced partition distribution in Beam job autoscaling
At the heart of this system is the adaptive scheduler, a component designed for rapid resource allocation. It intelligently adjusts the number of parallel tasks (parallelism) a job performs based on the availability of computing slots. These slots are like individual workstations, each capable of handling certain parts of the job.
However, we encountered a problem. Our jobs consist of multiple independent pipelines, each needing its own set of resources. Initially, the system tended to overburden the first few workers by assigning them more tasks, while others remained underutilized. This issue was due to the way Flink allocated tasks, favoring the first workers for each pipeline.

To address this issue, we developed a custom patch for Flink’s SlotSharingSlotAllocator, a component responsible for task distribution. This patch ensures a more balanced workload distribution across all available workers, improving efficiency and preventing bottlenecks. With this improvement, each worker gets a fair share of tasks, leading to better resource utilization and smoother operation of our Beam Jobs.
Drain support in Kubernetes Operator with Flink
The challenge
In the world of data processing with Apache Flink, a common task is to manage and update data-processing jobs. These jobs could be either stateful, where they remember past data, or stateless, where they don’t.
In the past, when we needed to update or delete a Flink job managed by the Kubernetes Operator, the system saved the current state of the job using a savepoint or checkpoint. However, a crucial step was missing: the system didn’t stop the job from processing new data (this is what we mean by draining the job). This oversight could lead to two major issues:
- For stateful jobs: potential data inconsistencies, because the job might process new data that wasn’t accounted for in the savepoint
- For stateless jobs: data duplication, because the job might reprocess data it already processed
The solution: drain function
This is where the update referenced as FLINK-32700 is needed. This update introduced a drain function. Think of it as telling the job, “Finish what you’re currently processing, but don’t take on anything new.” Here’s how it works:
- Stop new data: The job stops reading new input.
- Mark the source: The job marks the source with an infinite watermark. Think of this watermark as a marker that tells the system that there’s no more new data to process.
- Propagate through the pipeline: This marker is then passed through the job’s processing pipeline, ensuring that every part of the job knows not to expect any new data.
This seemingly small change has a big impact. It ensures that when a job is updated or deleted, the data it processes remains consistent and accurate. This is crucial for any data-processing task, because it maintains the integrity and reliability of the data. Furthermore, in cases where the drainage fails, you can cancel the job without needing a savepoint, which adds a layer of flexibility and safety to the whole process.
Conclusion
As we conclude Part 2 of our series on building and managing Apache Beam Flink services on Kubernetes, it’s evident that the journey of implementing autoscaling has been both challenging and enlightening. The obstacles we faced, from understanding Apache Beam backlog metrics in the Flink Runner environment to addressing slow reads in high-traffic scenarios, pushed us to develop innovative solutions and deepen our understanding of streaming infrastructure.
Our exploration into the intricacies of checkpointing, Kafka Reader wait times, and unbalanced partition distribution revealed the complexities of autoscaling Beam jobs. These challenges prompted us to devise strategies like the adaptive timeout in KafkaIO and the balanced workload distribution in Flink’s SlotSharingSlotAllocator. Additionally, the introduction of the drain support in Kubernetes Operator with Flink marks a significant advancement in managing stateful and stateless jobs effectively.
This journey has not only enhanced the robustness and efficiency of our system but has also contributed valuable insights to the broader community working with Apache Beam and Flink. We hope that our experiences and solutions will aid others facing similar challenges in their projects.
Stay tuned for our next blog post, where we’ll delve into the specifics of autoscaling in Apache Beam. We’ll break down the concepts, strategies, and best practices to effectively scale your Beam jobs. Thank you for following our series, and we look forward to sharing more of our journey and learnings with you.
Acknowledgements
This is a large effort to build the new infrastructure and to migrate the large customer based applications from cloud provider managed streaming infrastructure to self-managed, Flink-based infrastructure at scale. Thanks the Palo Alto Networks CDL streaming team who helped to make this happen: Kishore Pola, Andrew Park, Hemant Kumar, Manan Mangal, Helen Jiang, Mandy Wang, Praveen Kumar Pasupuleti, JM Teo, Rishabh Kedia, Talat Uyarer, Naitik Dani, and David He.
Explore More:
Join the conversation and share your experiences on our Community or contribute to our ongoing projects on GitHub. Your feedback is invaluable. If you have any comments or questions about this series, please feel free to reach out to us via User Mailist
Stay connected with us for more updates and insights into Apache Beam, Flink, and Kubernetes.