



blog
2018/01/09
Apache Beam: A Look Back at 2017Anand Iyer
&
Jean-Baptiste Onofré [@jbonofre]
On January 10, 2017, Apache Beam got promoted as a Top-Level Apache Software Foundation project. It was an important milestone that validated the value of the project, legitimacy of its community, and heralded its growing adoption. In the past year, Apache Beam has been on a phenomenal growth trajectory, with significant growth in its community and feature set. Let us walk you through some of the notable achievements.
Use cases
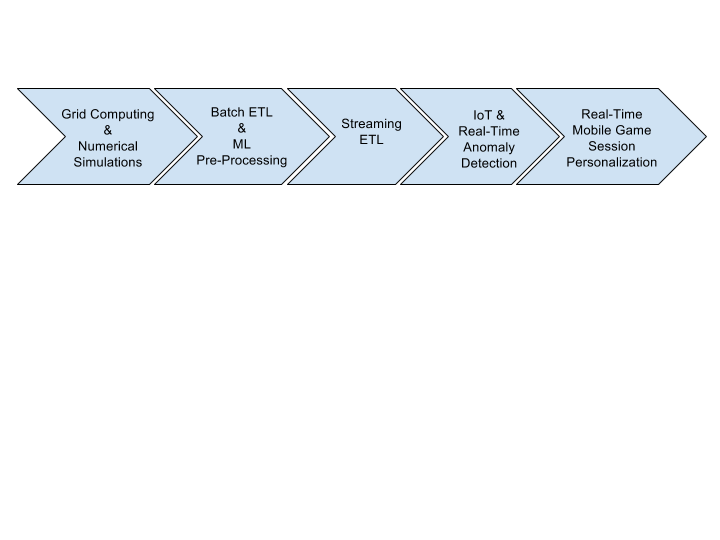
First, lets take a glimpse at how Beam was used in 2017. Apache Beam being a unified framework for batch and stream processing, enables a very wide spectrum of diverse use cases. Here are some use cases that exemplify the versatility of Beam.
Community growth
In 2017, Apache Beam had 174 contributors worldwide, from many different organizations. As an Apache project, we are proud to count 18 PMC members and 31 committers. The community had 7 releases in 2017, each bringing a rich set of new features and fixes.
The most obvious and encouraging sign of the growth of Apache Beam’s community, and validation of its core value proposition of portability, is the addition of significant new runners (i.e. execution engines). We entered 2017 with Apache Flink, Apache Spark 1.x, Google Cloud Dataflow, Apache Apex, and Apache Gearpump. In 2017, the following new and updated runners were developed:
- Apache Spark 2.x update
- IBM Streams runner
- MapReduce runner
- JStorm runner
In addition to runners, Beam added new IO connectors, some notable ones being the Cassandra, MQTT, AMQP, HBase/HCatalog, JDBC, Solr, Tika, Redis, and Elasticsearch connectors. Beam’s IO connectors make it possible to read from or write to data sources/sinks even when they are not natively supported by the underlying execution engine. Beam also provides fully pluggable filesystem support, allowing us to support and extend our coverage to HDFS, S3, Azure Storage, and Google Storage. We continue to add new IO connectors and filesystems to extend the Beam use cases.
A particularly telling sign of the maturity of an open source community is when it is able to collaborate with multiple other open source communities, and mutually improve the state of the art. Over the past few months, the Beam, Calcite, and Flink communities have come together to define a robust spec for Streaming SQL, with engineers from over four organizations contributing to it. If, like us, you are excited by the prospect of improving the state of streaming SQL, please join us!
In addition to SQL, new XML and JSON based declarative DSLs are also in PoC.
Continued innovation
Innovation is important to the success on any open source project, and Beam has a rich history of bringing innovative new ideas to the open source community. Apache Beam was the first to introduce some seminal concepts in the world of big-data processing:
- Unified batch and streaming SDK that enables users to author big-data jobs without having to learn multiple disparate SDKs/APIs.
- Cross-Engine Portability: Giving enterprises the confidence that workloads authored today will not have to be re-written when open source engines become outdated and are supplanted by newer ones.
- Semantics essential for reasoning about unbounded unordered data, and achieving consistent and correct output from a streaming job.
In 2017, the pace of innovation continued. The following capabilities were introduced:
- Cross-Language Portability framework, and a Go SDK developed with it.
- Dynamically Shardable IO (SplittableDoFn)
- Support for schemas in PCollection, allowing us to extend the runner capabilities.
- Extensions addressing new use cases such as machine learning, and new data formats.
Areas of improvement
Any retrospective view of a project is incomplete without an honest assessment of areas of improvement. Two aspects stand out:
- Helping runners showcase their individual strengths. After all, portability does not imply homogeneity. Different runners have different areas in which they excel, and we need to do a better job of helping them highlight their strengths.
- Based on the previous point, helping customers make a more informed decision when they select a runner or migrate from one to another.
In 2018, we aim to take proactive steps to improve the above aspects.
Ethos of the project and its community
The world of batch and stream big-data processing today is reminiscent of the Tower of Babel parable: a slowdown of progress because different communities spoke different languages. Similarly, today there are multiple disparate big-data SDKs/APIs, each with their own distinct terminology to describe similar concepts. The side effect is user confusion and slower adoption.
The Apache Beam project aims to provide an industry standard portable SDK that will:
- Benefit users by providing innovation with stability: The separation of SDK and engine enables healthy competition between runners, without requiring users to constantly learn new SDKs/APIs and rewrite their workloads to benefit from new innovation.
- Benefit big-data engines by growing the pie for everyone: Making it easier for users to author, maintain, upgrade and migrate their big-data workloads will lead to significant growth in the number of production big-data deployments.