



blog
2023/10/02
DIY GenAI Content Discovery Platform with Apache BeamPablo Rodriguez Defino
&
Namita Sharma
DIY GenAI Content Discovery Platform with Apache Beam
Your digital assets, such as documents, PDFs, spreadsheets, and presentations, contain a wealth of valuable information, but sometimes it’s hard to find what you’re looking for. This blog post explains how to build a DIY starter architecture, based on near real-time ingestion processing and large language models (LLMs), to extract meaningful information from your assets. The model makes the information available and discoverable through a simple natural language query.
Building a near real-time processing pipeline for content ingestion might seem like a complex task, and it can be. To make pipeline building easier, the Apache Beam framework exposes a set of powerful constructs. These constructs remove the following complexities: interacting with multiple types of content sources and destinations, error handling, and modularity. They also maintain resiliency and scalability with minimal effort. You can use an Apache Beam streaming pipeline to complete the following tasks:
- Connect to the many components of a solution.
- Quickly process content ingestion requests of documents.
- Make the information in the documents available a few seconds after ingestion.
LLMs are often used to extract content and summarize information stored in many different places. Organizations can use LLMs to quickly find relevant information disseminated in multiple documents written across the years. The information might be in different formats, or the documents might be too long and complex to read and understand quickly. Use LLMs to process this content to make it easier for people to find the information that they need.
Follow the steps in this guide to create a custom scalable solution for data extraction, content ingestion, and storage. Learn how to kickstart the development of a LLM-based solution using Google Cloud products and generative AI offerings. Google Cloud is designed to be simple to use, scalable, and flexible, so you can use it as a starting point for further expansion or experimentation.
High-level Flow
In this workflow, content uptake and query interactions are completely separated. An external content owner can send documents stored in Google Docs or in a binary text format and receive a tracking ID for the ingestion request. The ingestion process gets the content of the document and creates chunks that are configurable in size. Each document chunk is used to generate embeddings. These embeddings represent the content semantics, in the form of a vector of 768 dimensions. Given the document identifier and the chunk identifier, you can store the embeddings in a Vector database for semantic matching. This process is central to contextualizing user inquiries.
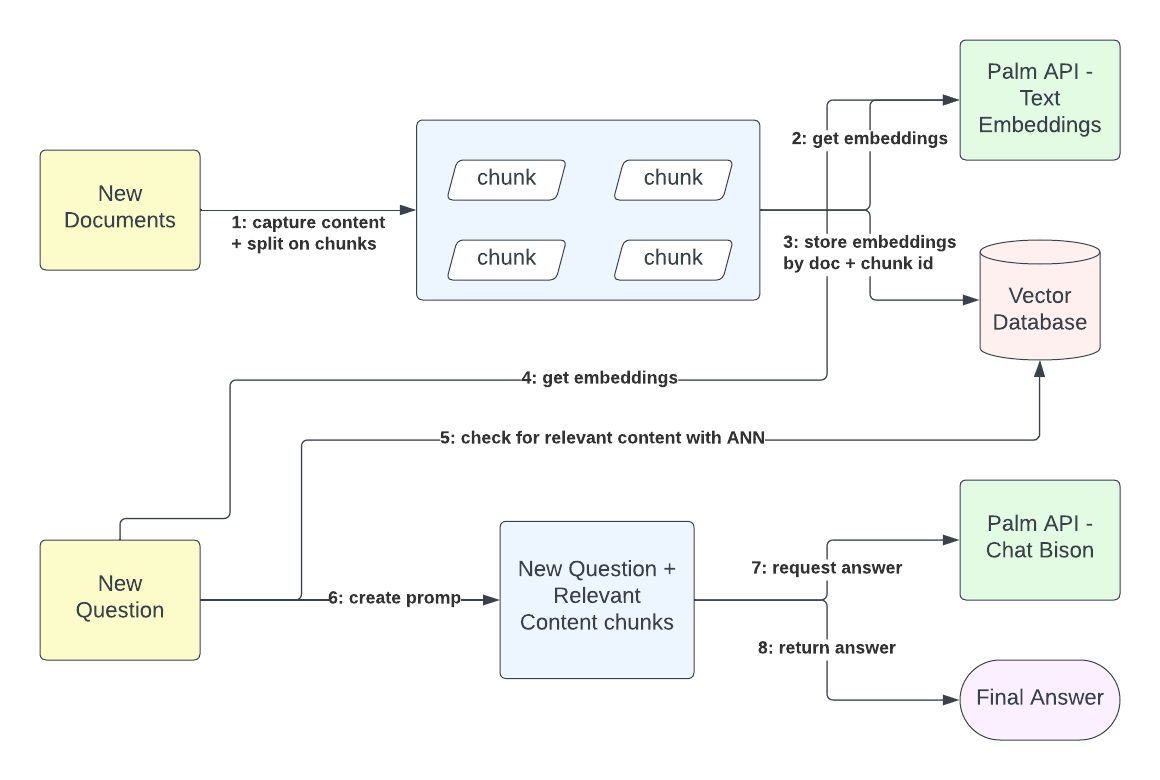
The query resolution process doesn’t depend directly on information ingestion. The user receives relevant answers based on the content ingested until the moment of the query request. Even if the platform doesn’t have any relevant content stored, the platform returns an answer stating that it doesn’t have relevant content. Therefore, the query resolution process first generates embeddings from the query content and from the previously existing context, like previous exchanges with the platform, then matches these embeddings with the existing embedding vectors stored from the content. When the platform has positive matches, it retrieves the plain-text content represented by the content embeddings. Finally, by using the textual representation of the query and the textual representation of the matched content, the platform formulates a request to the LLM to provide a final answer to the original user inquiry.
Components of the solution
Use the low-ops capabilities of the Google Cloud services to create a set of highly scalable features. You can separate the solution into two main components: the service layer and the content ingestion pipeline. The service layer acts as the entry point for document ingestion and user queries. It’s a simple set of REST resources exposed through Cloud Run and implemented by using Quarkus and the client libraries to access other services (Vertex AI models, Cloud Bigtable and Pub/Sub). The content ingestion pipeline includes the following components:
- A streaming pipeline that captures user content from wherever it resides.
- A process that extracts meaning from this content as a set of multi-dimensional vectors (text embeddings).
- A storage system that simplifies context matching between knowledge content and user inquiries (a Vector Database).
- Another storage system that maps knowledge representation with the actual content, forming the aggregated context of the inquiry.
- A model capable of understanding the aggregated context and, through prompt engineering, delivering meaningful answers.
- HTTP and gRPC-based services.
Together, these components provide a comprehensive and simple implementation for a content discovery platform.
Workflow Architecture
This section explains how the different components interact.
Dependencies of the components
The following diagram shows all of the components that the platform integrates with. It also shows all of the dependencies that exist between the components of the solution and the Google Cloud services.
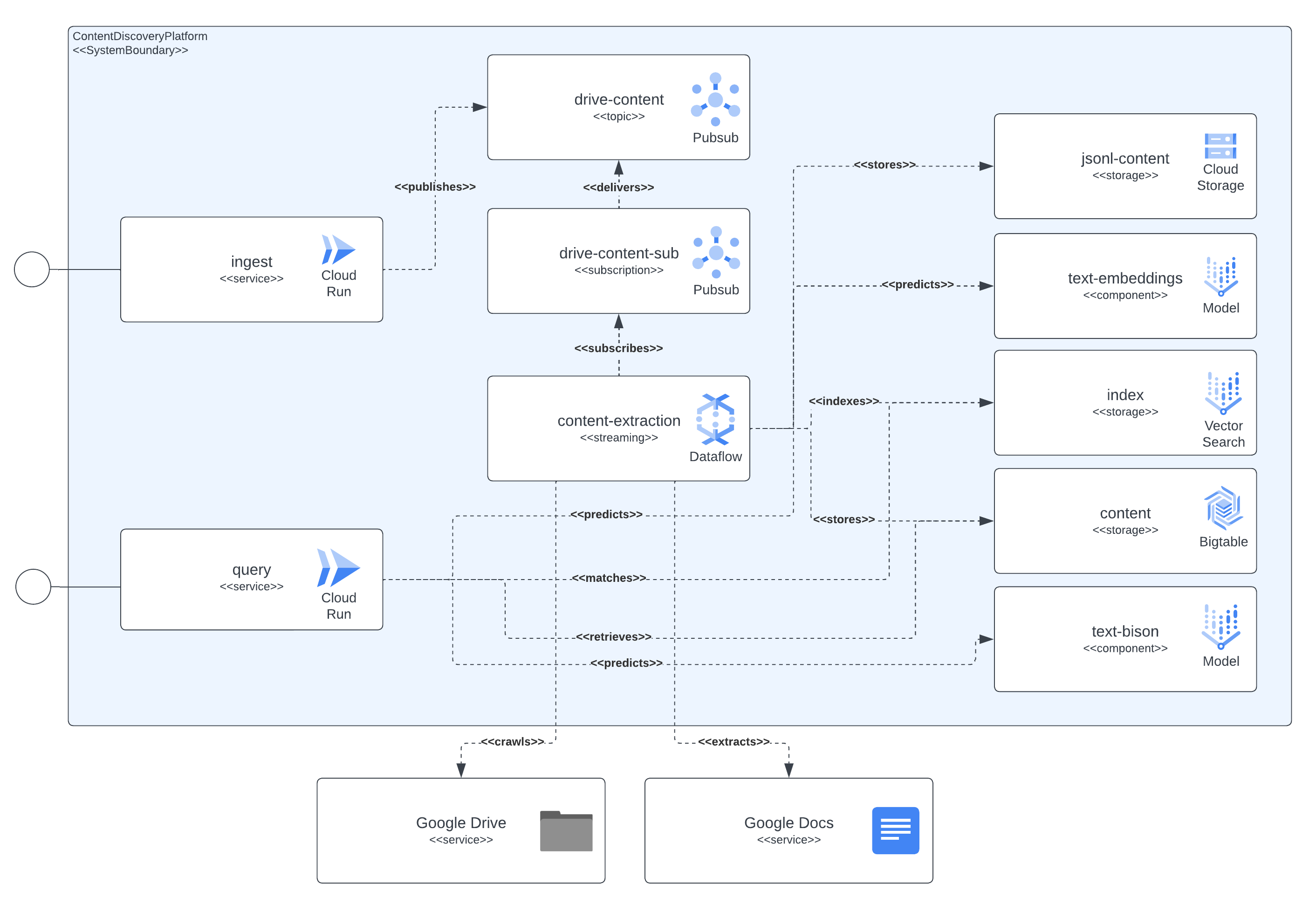
As seen in the diagram, the context-extraction component is the central aspect in charge of retrieving the document’s content, also their semantic meaning from the embedding’s model and storing the relevant data (chunks text content, chunks embeddings, JSON-L content) in the persistent storage systems for later use. PubSub resources are the glue between the streaming pipeline and the asynchronous processing, capturing the user ingestion requests, retries from potential errors from the ingestion pipeline (like the cases on where documents have been sent for ingestion but the permission has not been granted yet, triggering a retry after some minutes) and content refresh events (periodically the pipeline will scan the ingested documents, review the latest editions and define if a content refresh should be triggered).
The context-extraction component retrieves the content of the documents, diving it in chunks. It also computes embeddings, using the LLM interaction, from the extracted content. Then it stores the relevant data (chunks text content, chunks embeddings, JSON-L content) in the persistent storage systems for later use. Pub/Sub resources connect the streaming pipeline and the asynchronous processing, capturing the following actions:
- user ingestion requests
- retries from errors from the ingestion pipeline, such as when documents are sent for ingestion but access permissions are missing
- content refresh events (periodically the pipeline scans the ingested documents, reviews the latest editions, and decides whether to trigger a content refresh)
Also, CloudRun plays an important role exposing the services, interacting with many Google Cloud services to resolve the user query or ingestion requests. For example, while resolving a query request the service will:
- Request the computation of embeddings from the user’s query by interacting with the embeddings model
- Find near neighbor matches from the Vertex AI Vector Search (formerly Matching Engine) using the query embeddings representation
- Retrieve the text content from BigTable for those matched vectors, using their identifier, in order contextualize a LLM prompt
- And finally create a request to the VertexAI Chat-Bison model, generating the response the system will delivery to the user’s query.
Google Cloud products
This section describes the Google Cloud products and services used in the solution and what purpose they serve.
Cloud Build: All container images, including services and pipelines, are built directly from source code by using Cloud Build. Using Cloud Build simplifies code distribution during the deployment of the solution.
CloudRun: The solution’s service entry points are deployed and automatically scaled by CloudRun.
Pub/Sub: A Pub/Sub topic and subscription queue all of the ingestion requests for Google Drive or self-contained content and deliver the requests to the pipeline.
Dataflow: A multi-language, streaming Apache Beam pipeline processes the ingestion requests. These requests are sent to the pipeline from the Pub/Sub subscription. The pipeline extracts content from Google Docs, Google Drive URLs, and self-contained binary encoded text content. It then produces content chunks. These chunks are sent to one of the Vertex AI foundational models for the embedding representation. The embeddings and chunks from the documents are sent to Vertex AI Vector Search and to Cloud Bigtable for indexing and rapid access. Finally, the ingested documentation is stored in Google Cloud Storage in JSON-L format, which can be used to fine-tune the Vertex AI models. By using Dataflow to run the Apache Beam streaming pipeline, you minimize the ops needed to scale resources. If you have a burst on ingestion requests, Dataflow can keep the latency less than a minute.
Vertex AI - Vector Search: Vector Search is a high-performance, low-latency vector database. These vector databases are often called vector similarity search or approximate nearest neighbor (ANN) services. We use a Vector Search Index to store all the ingested documents embeddings as a meaning representation. These embeddings are indexed by chunk and document id. Later on, these identifiers can be used to contextualize the user queries and enrich the requests made to a LLM by providing knowledge extracted directly from the document’s content mappings stored on BigTable (using the same chunk-document identifiers).
Cloud BigTable: This storage system provides a low latency search by identifier at a predictable scale. Is a perfect fit, given the low latency of the requests resolution, for online exchanges between user queries and the platform component interactions. It used to store the content extracted from the documents since it’s indexed by chunk and document identifier. Every time a user makes a request to the query service, and after the query text embeddings are resolved and matched with the existing context, the document and chunk ids are used to retrieve the document’s content that will be used as context to request an answer to the LLM in use. Also, BigTable is used to keep track of the conversational exchanges between users and the platform, furthermore enriching the context included on the requests sent to the LLMs (embeddings, summarization, chat Q&A).
Vertex AI - Text Embedding Model: Text embeddings are a condensed vector (numeric) representation of a piece of text. If two pieces of text are semantically similar, their corresponding embeddings will be located close together in the embedding vector space. For more details please see get text embeddings. These embeddings are directly used by the ingestion pipeline when processing the document’s content and the query service as an input to match the users query semantic with existing content indexed in Vector Search.
Vertex AI - Text Summarization Model: Text-bison is the name of the PaLM 2 LLM that understands, summarizes and generates text. The types of content that text-bison can create include document summaries, answers to questions, and labels that classify the provided input content. We used this LLM to summarize the previously maintained conversation with the goal of enriching the user’s queries and better embedding matching. In summary, the user does not have to include all the context of his question, we extract and summarize it from the conversation history.
Vertex AI - Text Chat Model: Chat-bison is the PaLM 2 LLM that excels at language understanding, language generation, and conversations. This chat model is fine-tuned to conduct natural multi-turn conversations, and is ideal for text tasks about code that require back-and-forth interactions. We use this LLM to provide answers to the queries made by users of the solution, including the conversation history between both parties and enriching the model’s context with the content stored in the solution.
Extraction Pipeline
The content extraction pipeline is the platform’s centerpiece. It takes care of handling content ingestion requests, extracting documents content and computing embeddings from that content, to finally store the data in specialized storage systems that will be used in the query service components for rapid access.
High Level View
As previously mentioned the pipeline is implemented using Apache Beam framework and runs in streaming fashion on GCP’s Dataflow service.
By using Apache Beam and Dataflow we can ensure minimal latency (sub minute processing times), low ops (no need to manually scale up or down the pipeline when traffic spikes occur with time, worker recycle, updates, etc.) and with high level of observability (clear and abundant performance metrics are available).
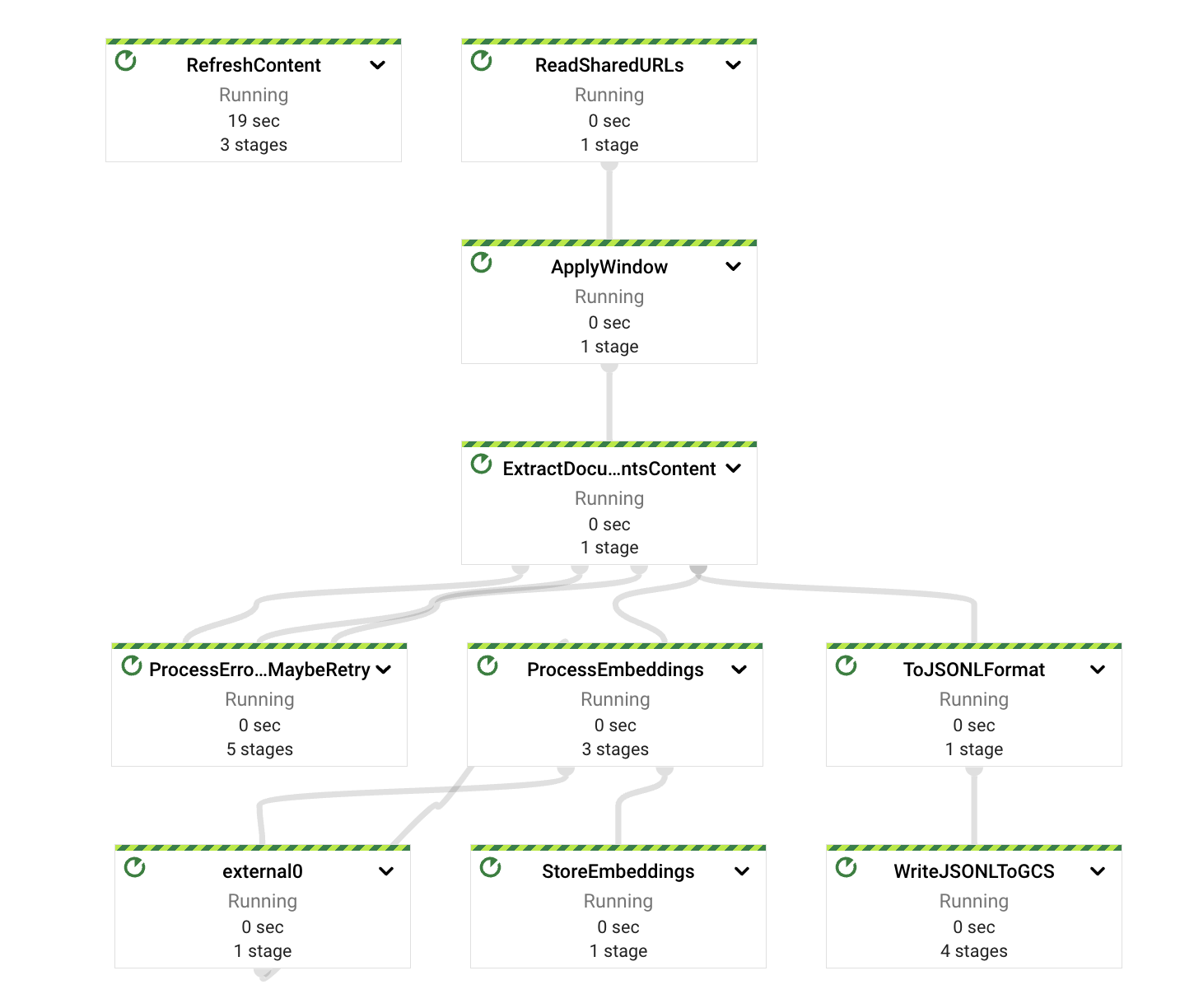
On a high level, the pipeline separates the extraction, computing, error handling and storage responsibilities on different components or PTransforms. As seen in the diagram, the messages are read from a PubSub subscription and immediately afterwards are included in the window definition before the content extraction.
Each of those PTransforms can be expanded to reveal more details regarding the underlying stages for the implementation. We will dive into each in the following sections.
The pipeline was implemented using a multi-language approach, with the main components written in the Java language (JDK version 17) and those related with the embeddings computations implemented in Python (version 3.11) since the Vertex AI API clients are available for this language.
Content Extraction
The content extraction component is in charge of reviewing the ingestion request payload and deciding (given the event properties) if it will need to retrieve the content from the event itself (self-contained content, text based document binary encoded) or retrieve it from Google Drive.
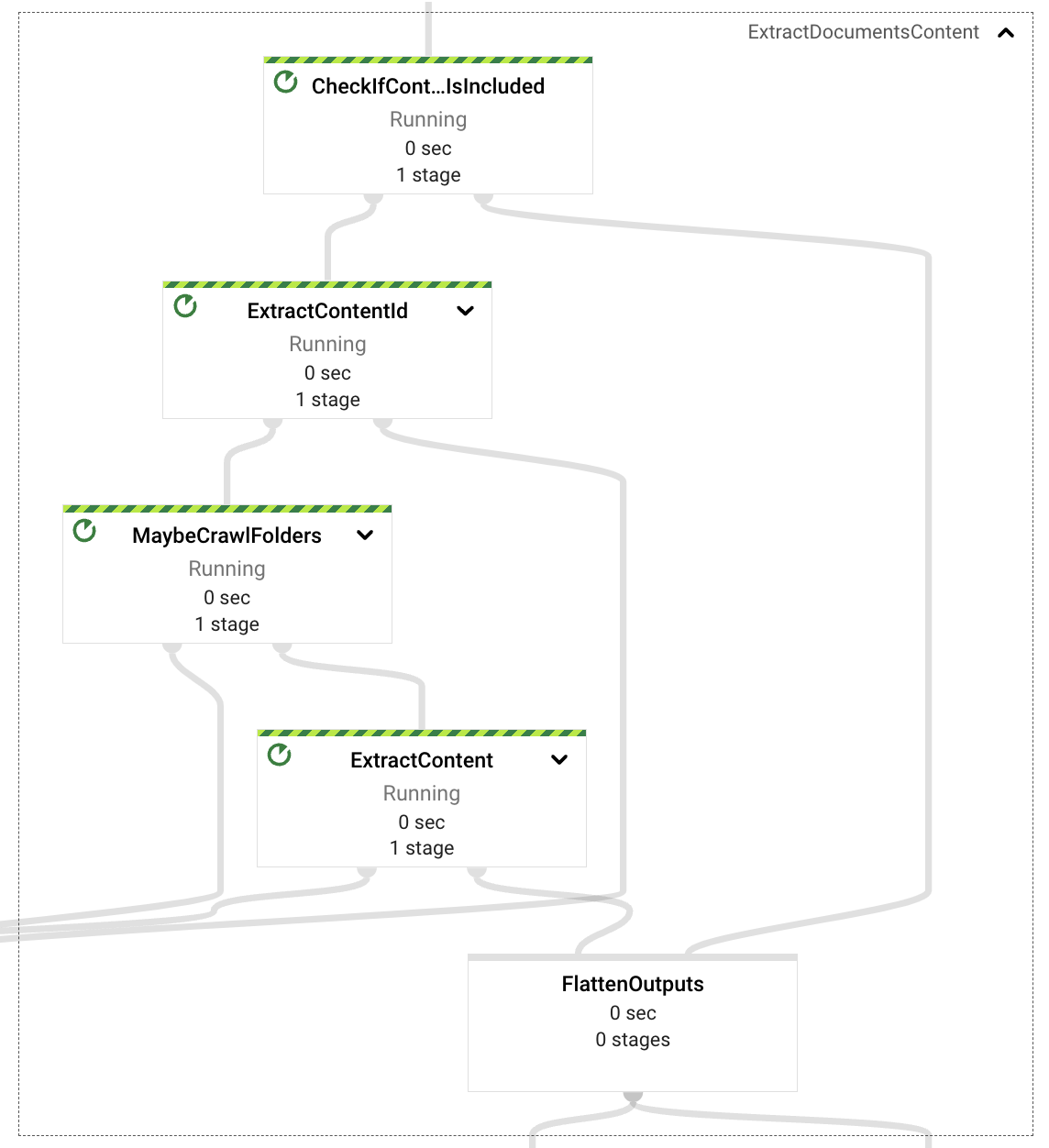
In case of a self-contained document, the pipeline will extract the document id and format the document in paragraphs for later embedding processing.
When in need of retrieval from Google Drive, the pipeline will inspect if the provided URL in the event refers to a Google Drive folder or a single file format (supported formats are Documents, Spreadsheets and Presentations). In the case of a folder, the pipeline will crawl the folder’s content recursively extracting all the files for the supported formats, in case of a single document will just return that one.
Finally, with all the file references retrieved from the ingestion request, textual content is extracted from the files (no image support implemented for this PoC). That content will also be passed to the embedding processing stages including the document’s identifier and the content as paragraphs.
Error Handling
On every stage of the content extraction process multiple errors can be encountered, malformed ingestion requests, non-conformant URLs, lack of permissions for Drive resources, lack of permissions for File data retrieval.
In all those cases a dedicated component will capture those potential errors and define, given the nature of the error, if the event should be retried or sent to a dead letter GCS bucket for later inspection.
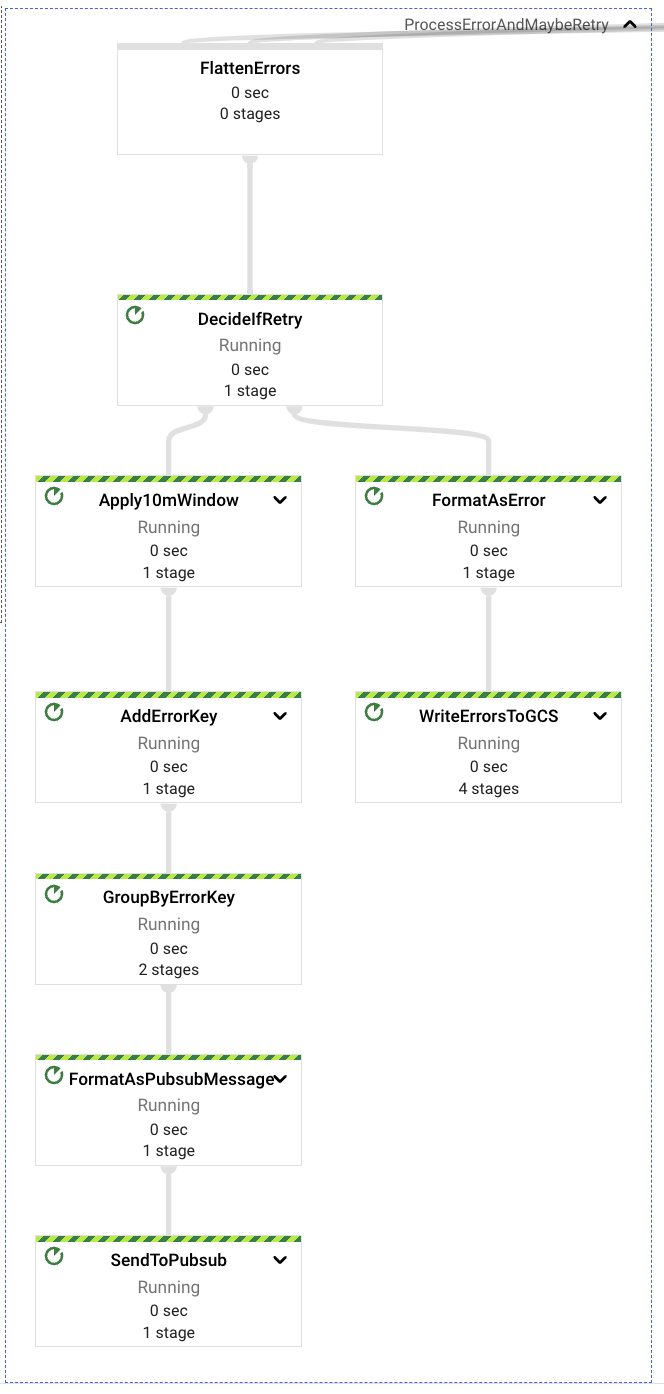
The final errors, or those which won’t be retried, are those errors related with bad request formats (the event itself or the properties content, like malformed or wrong URLs, etc.).
The retryable errors are those related with content access and lack of permissions. A request may have been resolved faster than the manual process of providing the right permissions to the Service Account that runs the pipeline to access the resources included in the ingestion request (Google Drive folders or files). In case of detecting a retryable error, the pipeline will hold the retry for 10 minutes before re-sending the message to the upstream PubSub topic; each error is retried at most 5 times before being sent to the dead letter GCS bucket.
In all cases of events ending on the dead letter destination, the inspection and re-processing must be done in a manual process.
Process Embeddings
Once the content has been extracted from the request, or captured from Google Drive files, the pipeline will trigger the embeddings computation process. As previously mentioned the interactions with the Vertex AI Foundational Models API is implemented in Python language. For this reason we need to format the extracted content in Java types that have a direct translation to those existing in the Python world. Those are key-values (in Python those are 2-element tuples), Strings (available in both languages), and iterables (also available in both languages). We could have implemented coders in both languages to support custom transport types, but we opted out of that in favor of clarity and simplicity.
Before computing the content’s embeddings we decided to introduce a Reshuffle step, making the output consistent to downstream stages, with the idea of avoiding the content extraction step being repeated in case of errors. This should avoid putting pressure on existing access quotas on Google Drive related APIs.
The pipeline will then chunk the content in configurable sizes and also configurable overlapping, good parameters are hard to get for generic effective data extraction, so we opted to use smaller chunks with small overlapping factor as the default settings to favor diversity on the document results (at least that’s what we see from the empirical results obtained).
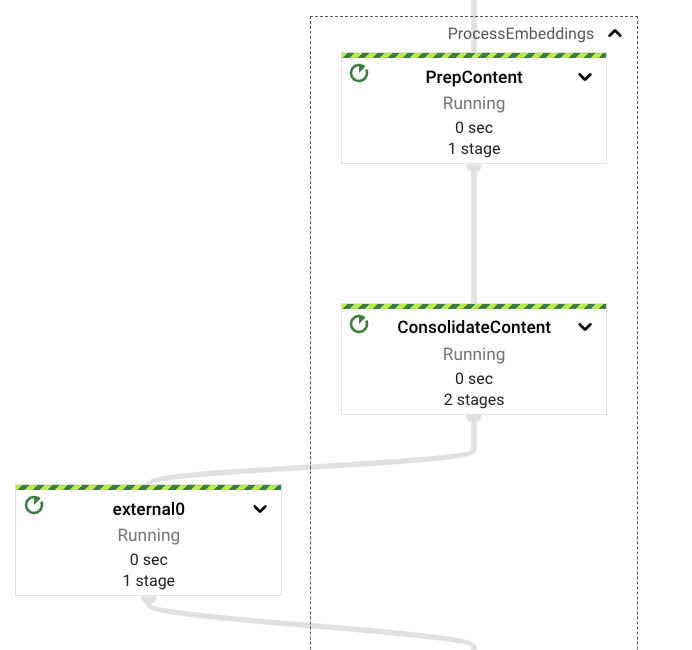
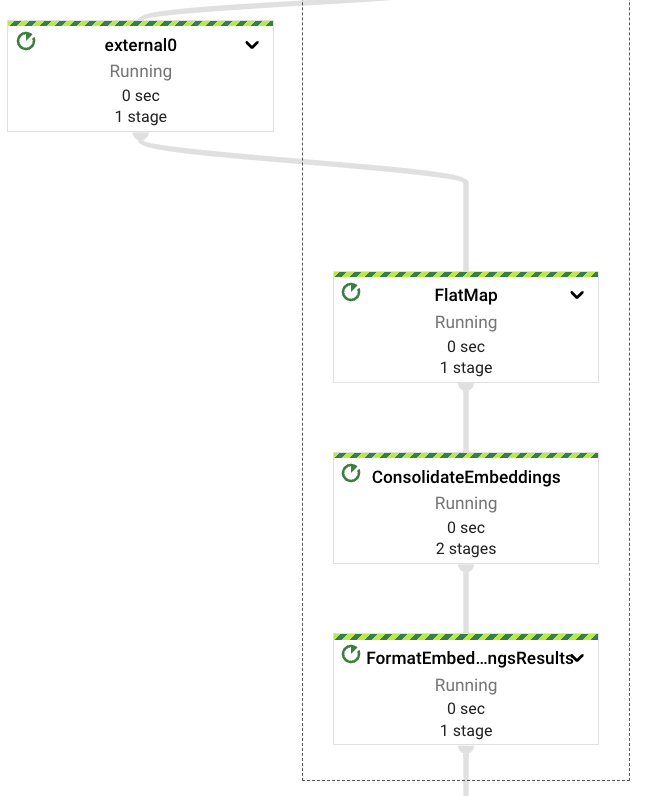
Once the embeddings vectors are retrieved from the embeddings Vertex AI LLM, we will consolidate them again avoiding repetition of this step in case of downstream errors.
Worth to notice that this pipeline is interacting directly with Vertex AI models using the client SDKs, Apache Beam already provides supports for this interactions through the RunInference PTransform (see an example here).
Content Storage
Once the embeddings are computed for the content chunks extracted from the ingested documents, we need to store the vectors in a searchable storage and also the textual content that correlates with those embeddings. We will be using the embeddings vectors as a semantic match later from the query service, and the textual content that corresponds to those embeddings for LLM context as a way to improve and guide the response expectations.
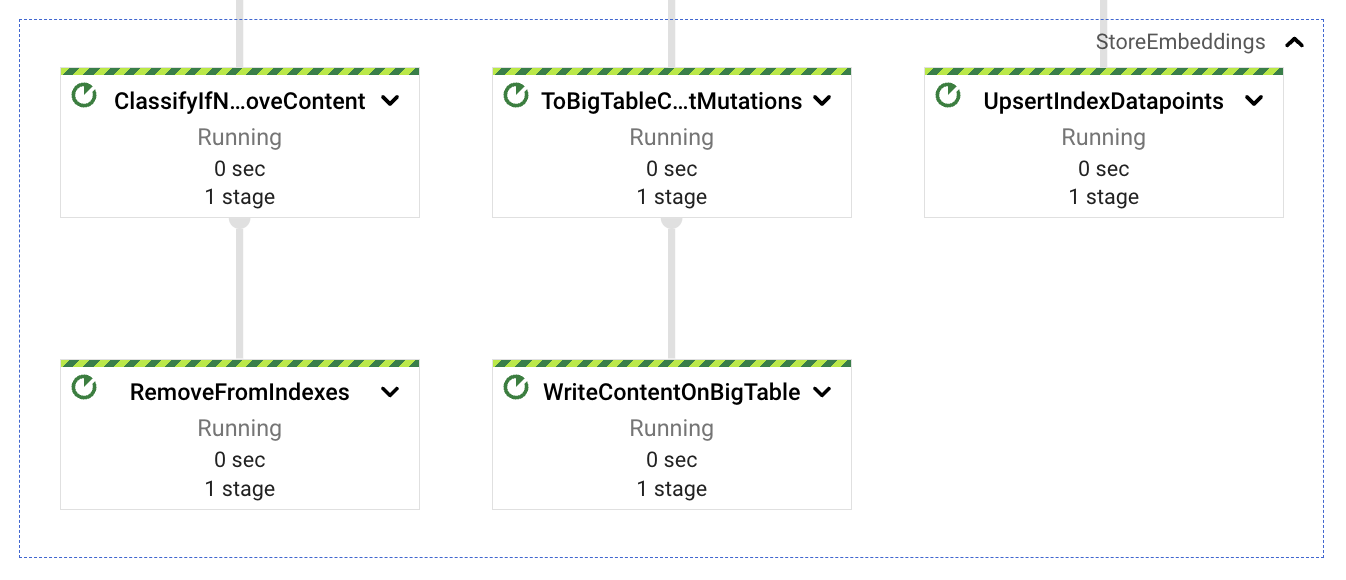
With that in mind is that in mind we split the consolidated embeddings into 3 paths, one that stores the vectors into Vertex AI Vector Search (using simple REST calls), another storing the textual content into BigTable (for low latency retrieval after semantic matching) and the final one as a potential clean up of content refresh or re ingestion (more on that later). The three paths are using the ingested document identifier as the correlating data on the actions, this key is formed by the document name (in case of available), the document identifier and the chunk sequence number. The reason for using identifiers for the chunk comes behind the idea of subsequent updates. An increase in the content will generate a larger number of chunks, and upserting all the chunks will enable always fresh data; on the contrary, a decrease in content will generate a smaller chunk count for the document’s content, this number difference can be used to delete the remaining orphan indexed chunks (from content no longer existing in the latest version of the document).
Content Refresh
The last pipeline component is the simplest, at least conceptually. After the documents from Google Drive gets ingested, an external user can produce updates in them, causing the indexed content to become out of date. We implemented a simple periodic process, inside the same streaming pipeline, that will take care of the review of already ingested documents and see if there are content updates needed. We use a GenerateSequence transform to produce a periodic impulse (every 6 hours by default), that will trigger a scan on BigTable retrieving all the ingested document identifiers. Given those identifiers we can then query Google Drive for the latest update timestamp of each document and use that marker to decide if an update is needed.
In case of needing to update the document’s content, we can simply send an ingestion request to the upstream PubSub topic and let the pipeline run its course for this new event. Since we are taking care of upserting embeddings and cleaning up those that no longer exist, we should be capable of taking care of the majority of the additions (as long those are text updates, image based content is not being processed as of now).
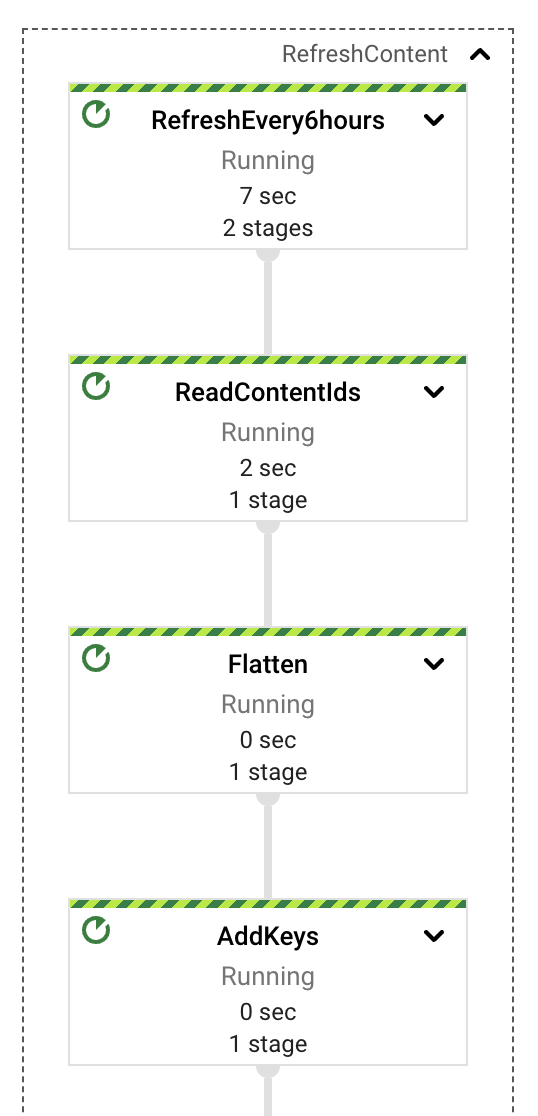
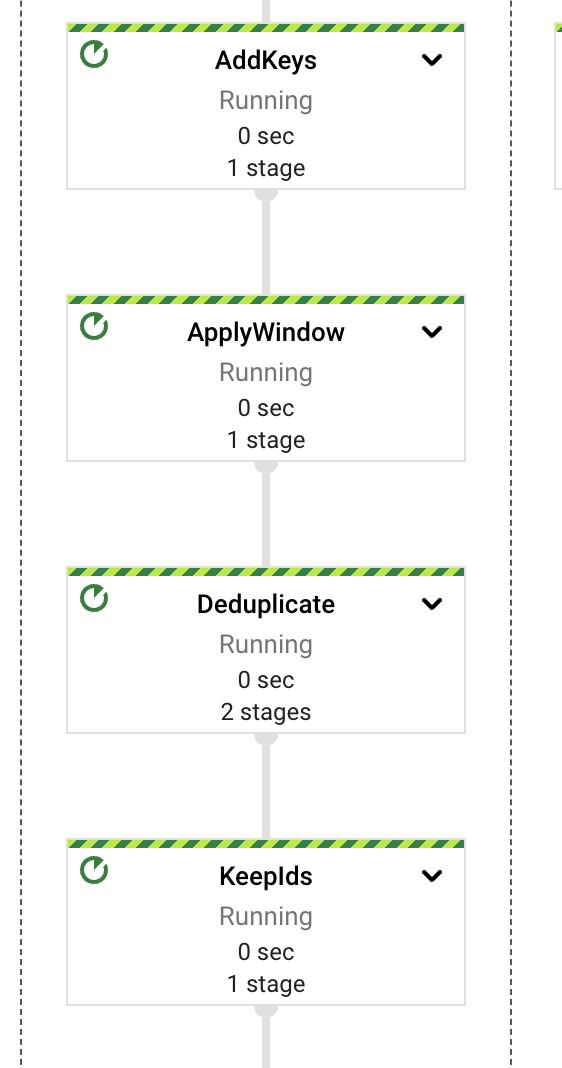
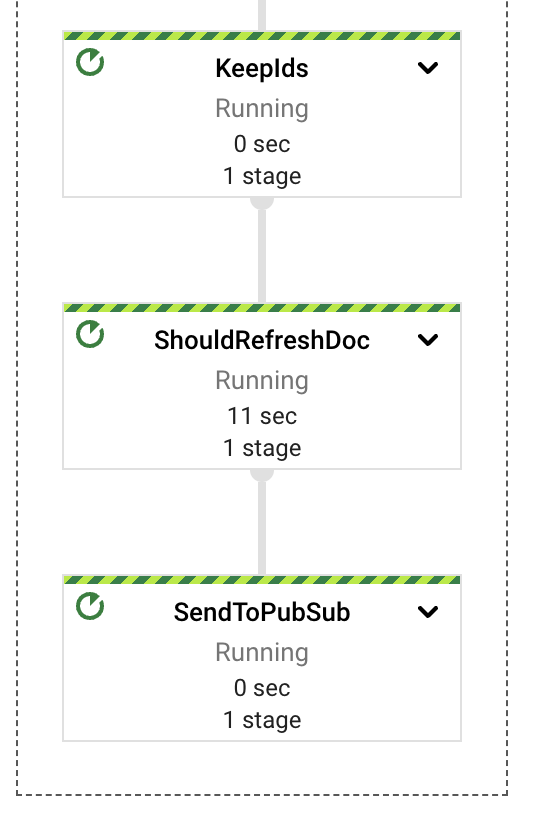
This task could be performed as a separate job, possibly one that is periodically scheduled in batch form. This would result in lower costs, a separate error domain, and more predictable auto scaling behavior. However, for the purposes of this demonstration, it is simpler to have a single job.
Next, we will be focusing on how the solution interacts with external clients for ingestion and content discovery use cases.
Interaction Design
The solution aims to make the interactions for ingesting and querying the platform as simple as possible. Also, since the ingestion part may imply interacting with several services and imply retries or content refresh, we decided to make both separated and asynchronous, freeing the external users of blocking themselves while waiting for requests resolutions.
Example Interactions
Once the platform is deployed in a GCP project, a simple way to interact with the services is through the use of a web client, curl is a good example. Also, since the endpoints are authenticated, a client needs to include its credentials in the request header to have its access granted.
Here is an example of an interaction for content ingestion:
$ > curl -X POST -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-identity-token)" https://<service-address>/ingest/content/gdrive -d $'{"url":"https://drive.google.com/drive/folders/somefolderid"}' | jq .
# response from service
{
"status": "Ingestion trace id: <some identifier>"
}
In this case, after the ingestion request has been sent to the PubSub topic for processing, the service will return the tracking identifier, which maps with the PubSub message identifier. Note the provided URL can be one of a Google Doc or a Google Drive folder, in the later case the ingestion process will crawl the folder’s content recursively to retrieve all the contained documents and their contents.
Next, an example of a content query interaction, very similar to the previous one:
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications", "sessionId": ""}' \
| jq .
# response from service
{
"content": "VertexAI Foundation Models are a set of pre-trained models that can be used to accelerate the development of machine learning applications. They are available for a variety of tasks, including natural language processing, computer vision, and recommendation systems.\n\nVertexAI Foundation Models can be used to improve the performance of Generative AI applications by providing a starting point for model development. They can also be used to reduce the amount of time and effort required to train a model.\n\nIn addition, VertexAI Foundation Models can be used to improve the accuracy and robustness of Generative AI applications. This is because they are trained on large datasets and are subject to rigorous quality control.\n\nOverall, VertexAI Foundation Models can be a valuable resource for developers who are building Generative AI applications. They can help to accelerate the development process, reduce the cost of development, and improve the performance and accuracy of applications.",
"previousConversationSummary": "",
"sourceLinks": [
{
"link": "<possibly some ingested doc url/id>",
"distance": 0.7233397960662842
}
],
"citationMetadata": [
{
"citations": []
}
],
"safetyAttributes": [
{
"categories": [],
"scores": [],
"blocked": false
}
]
}
The platform will answer the request with a textual response from the LLM and include as well information about the categorization, citation metadata and source links (if available) of the content used to generate the response (this are for example, Google Docs links of the documents previously ingested by the platform).
When interacting with the services, a good query will generally return good results, the clearer the query the easier it will be to contextualize its meaning and more accurate information will be sent to the LLMs to retrieve answers. But having to include all the details of the query context in a phrase on every exchange with the service can be very cumbersome and difficult. For that case the platform can use a provided session identifier that will be used to store all the previous exchanges between a user and the platform. This should help the implementation to better contextualize the initial query embeddings matching and even provide more concise contextual information in the model requests. Here is an example of a contextual exchange:
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.\n\nUsing VertexAI Foundational Models can help you to:\n\n* Reduce the time and effort required to develop Generative AI applications\n* Improve the accuracy and quality of your models\n* Access the latest research and development in Generative AI\n\nVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications.",
…
}
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"describe the available LLM models?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "The VertexAI Foundational Models suite includes a variety of LLM models, including:\n\n* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.\n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.\n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.\n\nThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools.",
…
}
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits).",
…
}
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"care to share the price?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models).",
…
}
Usage Tip: in case of abruptly changing topics, sometimes is better to use a new session identifier.
Deployment
As part of the platform solution, there are a set of scripts that help with the deployment of all the different components. By running the start.sh and setting the right parameters (GCP project, terraform state bucket and name for the platform instance) the script will take care of building the code, deploying the needed containers (service endpoint container and Dataflow python custom container), deploying all the GCP resources using Terraform and finally deploying the pipeline. There is also the possibility of modifying the pipeline’s execution by passing an extra parameter to the startup script, for example: start.sh <gcp project> <state-bucket-name> <a run name> "--update" will update the content extraction pipeline in-place.
Also, in case of wanting to focus only on the deployment of specific components other scripts have been included to help with those specific tasks (build the solution, deploy the infrastructure, deploy the pipeline, deploy the services, etc.).
Solution’s Notes
This solution is designed to serve as an example for learning purposes. Many of the configuration values for the extraction pipeline and security restrictions are provided only as examples. The solution doesn’t propagate the existing access control lists (ACLs) of the ingested content. As a result, all users that have access to the service endpoints have access to summarizations of the ingested content from those original documents.
Notes about the source code
The source code for the content discovery platform is available in Github. You can run it in any Google Cloud project. The repository includes the source code for the integration services, the multi-language ingestion pipeline, and the deployment automation through Terraform. If you deploy this example, it might take up to 90 minutes to create and configure all the needed resources. The README file contains additional documentation about the deployment prerequisites and example REST interactions.