



blog & python
2022/11/09
New Resources Available for Beam MLDanny McCormick
If you’ve been paying attention, over the past year you’ve noticed that
Beam has released a number of features designed to make Machine Learning
easy. Ranging from things like the introduction of the RunInference
transform to the continued refining of Beam Dataframes, this has been
an area where we’ve seen Beam make huge strides. While development has
advanced quickly, however, until recently there has been a lack of
resources to help people discover and use these new features.
Over the past several months, we’ve been hard at work building out documentation and notebooks to make it easier to use these new features and to show how Beam can be used to solve common Machine Learning problems. We’re now happy to present this new and improved Beam ML experience!
To get started, we encourage you to visit Beam’s new AI/ML landing page. We’ve got plenty of content on things like multi-model pipelines, performing inference with metrics, online training, and much more.
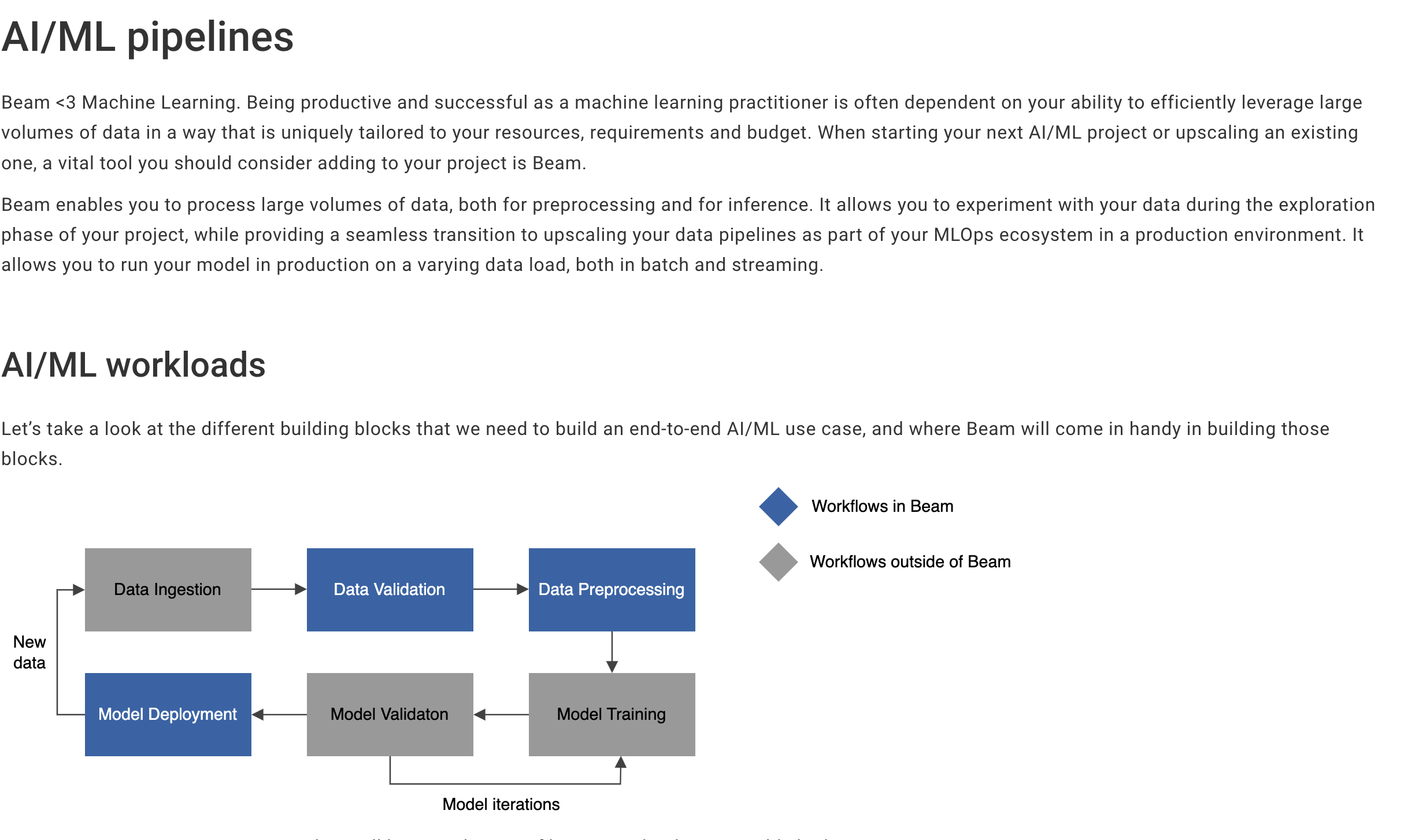
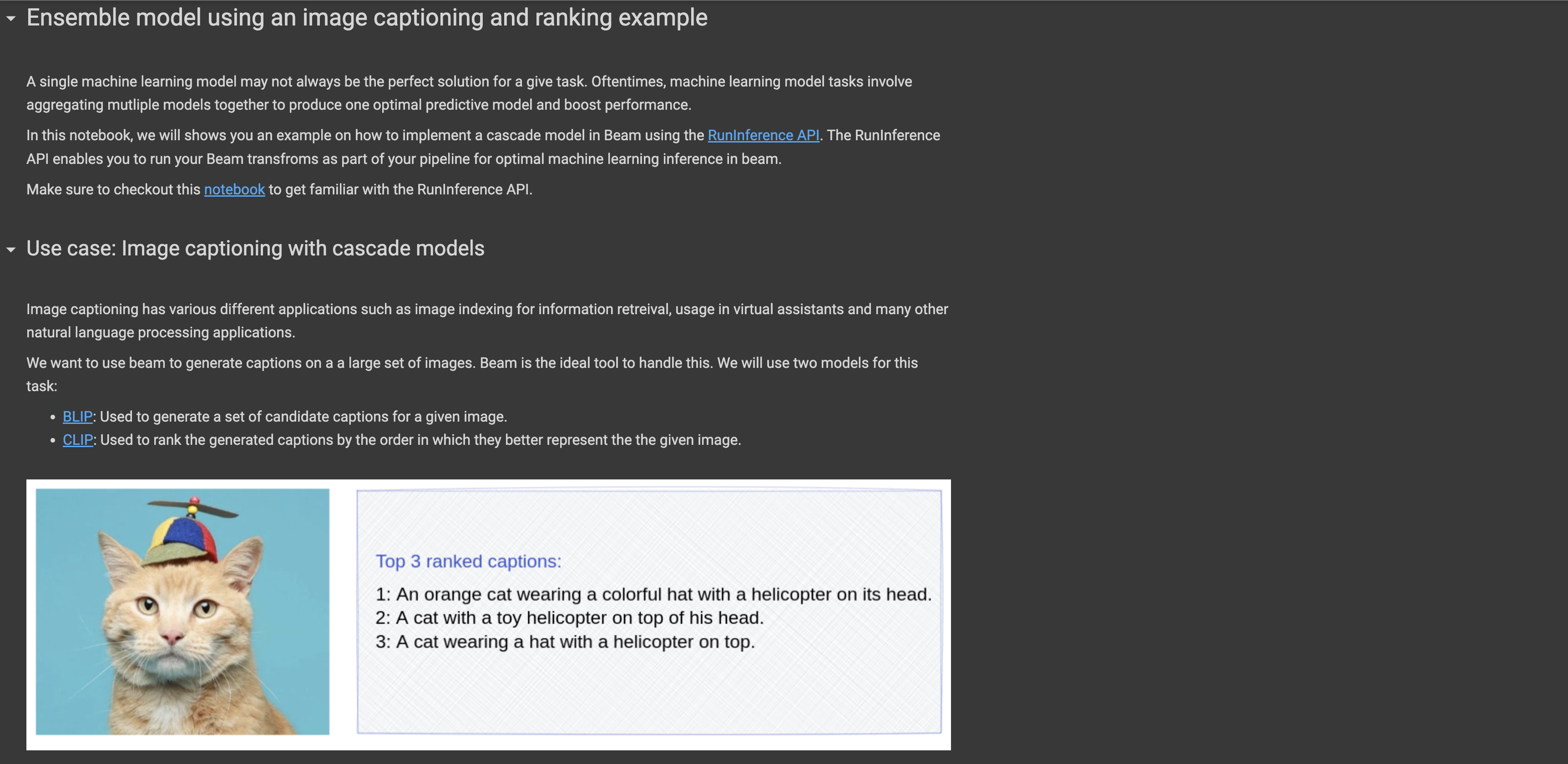
We’ve also introduced a number of example Jupyter Notebooks
showing how to use built in beam transforms like RunInference and Beam Dataframes.
Adding more examples and notebooks will be a point of emphasis going forward. For our next round of improvements, we are planning on adding examples of using RunInference with >30GB models, with multi-language pipelines, with common Beam concepts, and with TensorRT. We will also add examples showing other pieces of the Machine Learning lifecycle like model evaluation with TFMA, per-entity training, and more online training.
We hope you find this useful! As always, if you see any areas for improvement, please open an issue or a pull request!