




“We query across >2 petabytes of analytical data and several terabytes of transactional data, processing 1 billion events daily. Apache Beam enabled us to parallelize data processing, maximize throughput, and accelerate the movement/ETL of these datasets.”

Mass Ad Bidding With Beam at Booking.com
Background
Booking.com seamlessly connects millions of travelers to memorable experiences by investing in technology that takes the friction out of travel and making it easier for everyone to experience the world. Booking.com is a brand of Booking Holdings, the world’s largest provider of online travel & related services to consumers and local partners. To help people discover destinations in more than 220 countries and territories, Booking Holdings as a whole spent $5.99 billion in marketing in 2022, with Booking.com being a leading travel advertiser on Google Pay Per Click (PPC) Search Ads.
The PPC team at Booking.com’s Marketing Technology department is in charge of the infrastructure and internal tooling necessary to run PPC advertising at this scale. The PPC team’s primary goal is to reliably and efficiently optimize their PPC across all search engine providers, measure and analyze ad performance data, manage ad hierarchies, and adjust ad criteria. Apache Beam supports this goal by providing an effective abstraction that helps build reliable, performant, and cost-efficient data processing infrastructure at a very large scale.
Journey To Beam
PPC advertising is a business-critical promotional channel for Booking.com’s marketing. With billions of searches per day on search engines, they use PPC Search Ads to make sure users will get the most relevant offerings in their search results. Behind the scenes, the PPC team manages the operational infrastructure to process ad performance feedback, assess historical performance, support machine learning operations that generate bids, and communicate the bids back to a search engine provider.
The earlier implementation of Booking.com’s mass ad bidding was a custom stack batch pipeline, with MySQL data storage, cron scheduling, and Perl scripts to implement business logic. The design eventually hit the performance bottleneck struggling to keep up with the increasing throughput demands on bids per second. The lost opportunity cost combined with the cost of maintaining the complexity became larger than the cost of a full rewrite.
The mass bidding infrastructure had undergone several rewrites before Apache Beam came into play. The core idea behind the PPC team’s latest implementation of the Apache Beam-powered data ecosystem originated in late 2020. Attending Beam Summit and Beam College community events helped the team to learn about the open-source Apache Beam abstraction model that is also available as managed service with the Dataflow runner.
It was straightforward to introduce the idea to the rest of the team - the Apache Beam model is easy to understand because it isolates the business logic and helps build a mental model.

The PPC team decided to pilot this framework by creating a new prototype Java pipeline that downloads ad performance reports.
With Apache Beam, we achieved a multifactor speed-up in the development time. We were able to actually deliver one pipeline in a matter of 3 weeks. We would have spent a solid three months if we had to implement the pipeline using any other framework.

Once the first POC proved to be successful, the PPC team placed Apache Beam at the core of their data infrastructure. Spinning Dataflow managed service provided an opportunity to focus on new capabilities instead of maintaining their own compute and storage infrastructure. The Apache Beam abstraction from the runtime implementation details allows the PPC team to focus on business logic and leverage parallelism to easily scale horizontally. Heavy users of various GCP products, they also leveraged the Apache Beam I/O connectors to natively integrate with various sinks and sources, such as BiqQuery, Firestore, and Spanner.
Apache Beam serves as an effective abstraction for our data infrastructure and processing. With Dataflow runner, we also don’t need to worry about maintaining the runtime and storage infrastructure, as well as about cloud provider lock-in.

The quality of documentation, as well as the vibrant Apache Beam open-source community, lively discussions in mailing lists, and plenty of user-created content made it very easy to onboard new use cases.
The Apache Beam open source community, documentation, and Youtube content were very helpful when designing and implementing the new ecosystem.
Currently, Apache Beam powers batch and streaming pipelines for the PPC team’s large-scale ad bidding infrastructure.
Mass Ad Bidding
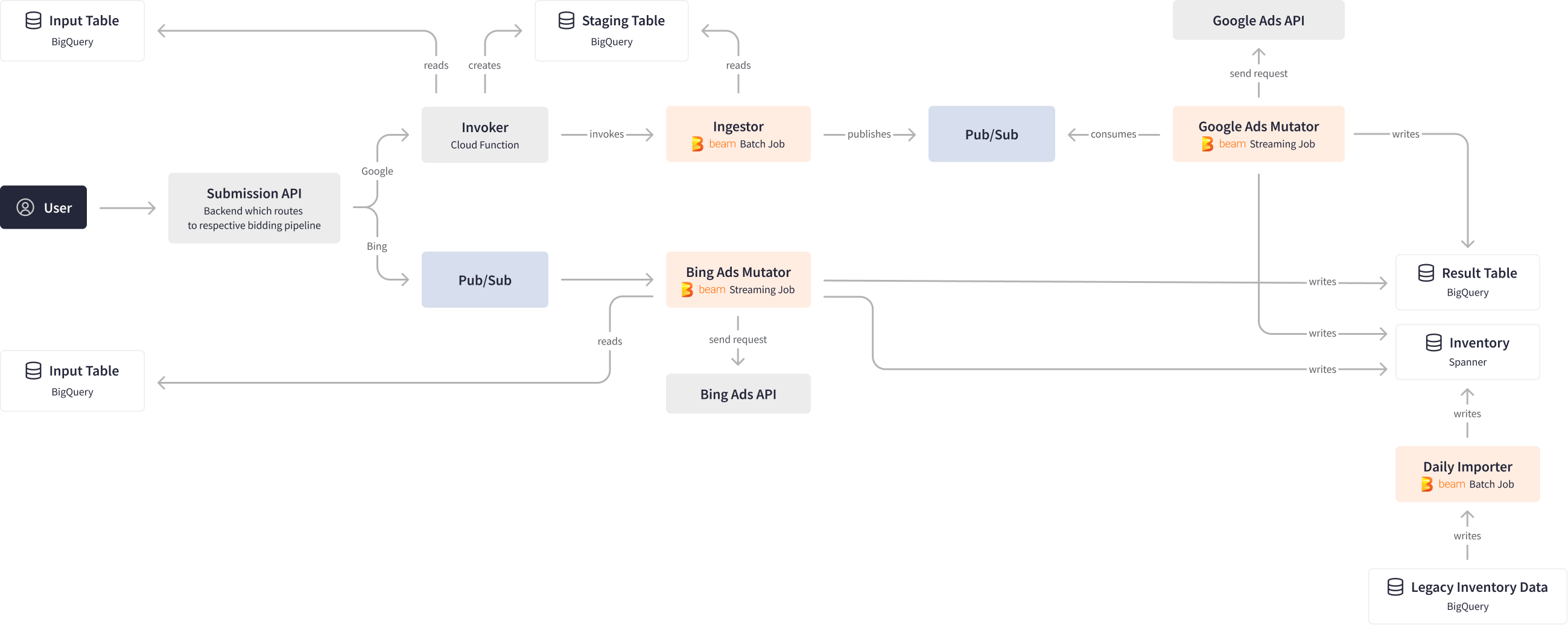
Conceptually, mass ad bidding infrastructure accepts ad bidding requests and assets and provides staging for submission to multiple services, processing ad performance results at a massive scale. The Ad bidding infrastructure relies on Apache Beam batch and streaming pipelines to interact with Big Query, Spanner, Firestore, Pub/Sub sources and sinks, and uses Beam’s stateful processing for ads services API calls.
When designing the data infrastructure, the PPC team’s primary goal was to maximize the throughput of bids per second while still respecting the request rate limits imposed by the search engines’ Ads APIs on the account level. The PPC team implemented streaming Apache Beam pipelines that utilize keyed PCollections to cluster outgoing Ads modifications by account ID, group them into batches, and execute data processing in parallel. This approach helped optimize the throughput for the team’s thousands of Ads accounts and achieve improved performance and reliability at scale.
Apache Beam enabled us to parallelize data processing and maximize throughput at a very large scale.

The PPC team uses an internal API interface to submit queries to the mass bidding infrastructure, which routes the queries to the respective ad bidding pipelines for Google and Bing. For the Google branch, the API calls an Invoker cloud function, which reads data from BigQuery, aggregates it, and performs analysis before storing intermediate results in staging tables in BigQuery. The Invoker then calls an Ingestor Apache Beam batch pipeline, which publishes the data into Pub/Sub.
On the other end, the Google Ad Mutator Apache Beam streaming pipeline listens to over 1 billion of Pub/Sub events per day and sends corresponding requests to the Google Ads API. This job is designed with backpressure in mind, ensuring optimal performance while also considering factors such as partitioning, parallelism, and key-ordered delivery guarantees. The results are then written to the Result Table in BigQuery and the Inventory in Spanner, with over 100 GB processed daily.
Finally, the Daily Importer Apache Beam batch pipeline grabs the inventory data and disseminates it for downstream tasks, also processing 100 GB daily. Data analysts then match the incoming stream of hotel reservations with the inventory data on what was advertised and evaluate PPC ads performance.
The versatility and flexibility of the Apache Beam framework are key to the entire process, as it allows for combining batch and streaming processing into a unified flow, while also enabling integration with a wide range of sources and destinations with different characteristics and semantics. The framework also provides guarantees for delivery and order, all at scale and with optimal tradeoffs for streaming processing.
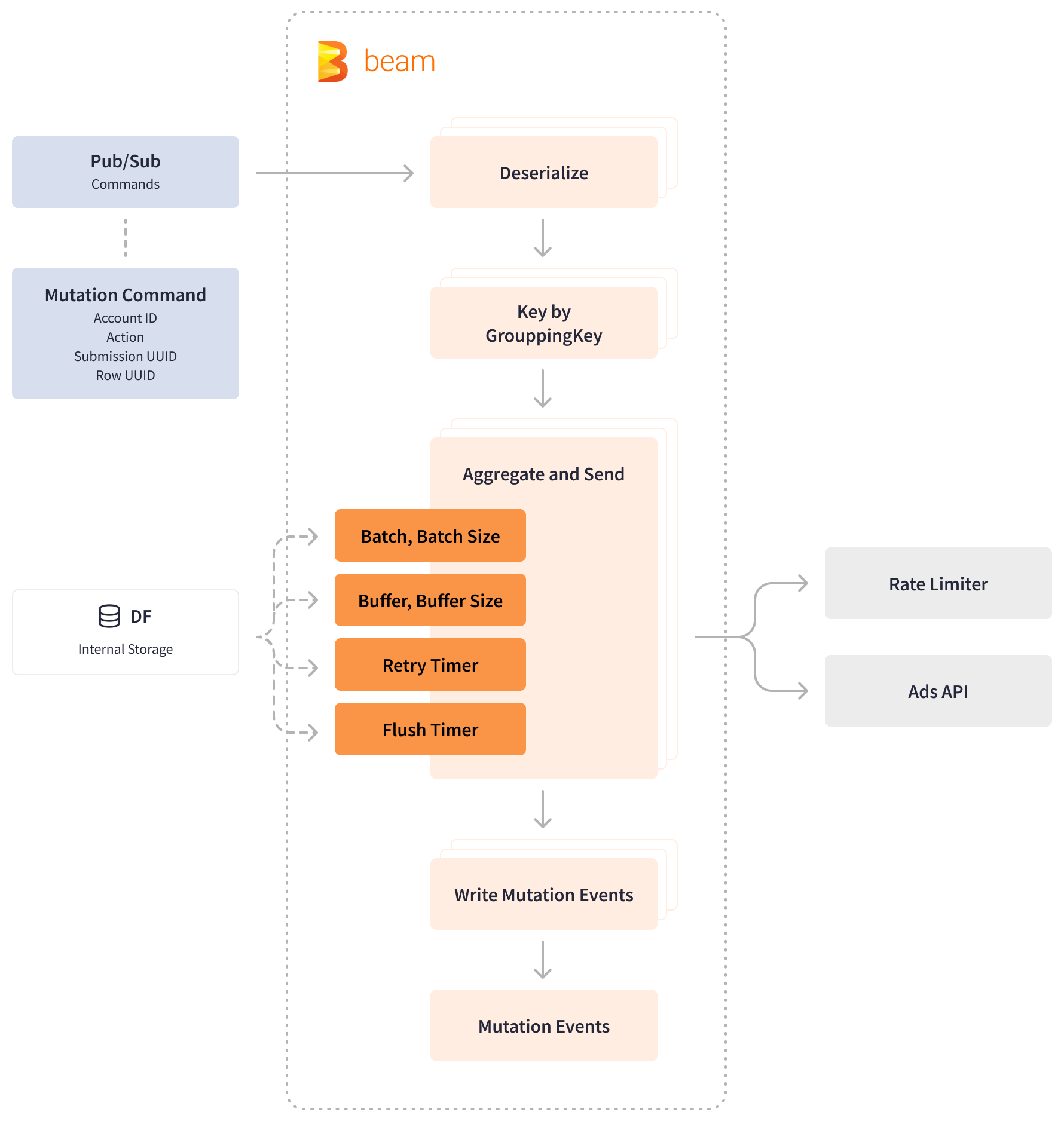
The Google Ads Mutator and Bing Ads Mutator pipelines are an integral part of Booking.com’s mass bidding infrastructure. These streaming Apache Beam pipelines process all the data coming to and from search engines’ Ads API and write massive ad performance reports to inventory in Cloud Spanner. The Apache Beam built-in Cloud Spanner SpannerIO. Write transform allows writing data more efficiently by grouping mutations into batches to maximize throughput while also respecting the Spanner per-transation limits. With Apache Beam reducing the key-range of the mutations, the PPC team was able to achieve cost optimization in Spanner and improve processing performance.
Similarly, to stay within the Ads API rate limit levels, the PPC team leverages the Apache Beam timely and stateful processing and a Redis-based microservice that maintains the rate limits for bids. The PPC team has a custom “Aggregate and Send” function that accumulates incoming mutation commands in the buffer until it is filled. The function requests mutation quota from the rate limiter and sends a request to the Ads API. If the internal rate limiter or the Ads API requests a wait, the function starts a retry timer and continues buffering incoming commands. If there are no requests to wait, the function clears the command buffer and publishes the queries to Pub/Sub.
Apache Beam provides windowed aggregations to pre-aggregate mutation commands and assures delivery guarantees through the use of timers and stateful operations. By using BagState, Apache Beam can add elements to a collection to accumulate an unordered set of mutations. ValueState, on the other hand, stores typed values for batch, batch size, and buffer size that can be read and modified within the DoFn’s ProcessElement and OnTimer methods.
Runners that support paged reads can handle individual bags that are larger than available memory. The Apache Beam retry timer is used to output data buffered in state after some amount of processing time. The flush timer is used to prevent commands from remaining in the buffer for too long, particularly when the commands are infrequent and unable to fill the buffer.
The stateful capabilities of Beam model allowed us to gain fine-grained control over bids per second by buffering the incoming data until it can be consumed, and maintain a higher processing performance than the other potential solutions.
To increase observability and provide users with a way to monitor their submission status, the PPC team also developed a custom function that produces metrics with custom keys to count the number of received and sent requests. Apache Beam extensibility allowed the PPC team to implement this supplementary monitoring tool right inside the Ad Mutator pipelines as an additional block.
Results
Apache Beam powers the data logistics behind Booking.com’s massive performance marketing “flywheel” with 1M+ queries monthly for ad bidding workflows across multiple data systems scanning 2 PB+ of analytical data and terabytes of transactional data daily, processing over 1 billion events at thousands of messages per second at peak.
Apache Beam provided the much-needed parallelism, connectivity, and partitioning capabilities, as well as strong key-ordered delivery guarantees, to parallelize processing for several thousands of Booking.com’s Ads accounts, optimize costs, and ensure performance and reliability for ad bids processing at scale.
Apache Beam accelerated processing time for the streaming pipelines from 6 hours to 10 minutes, which is an eye-opening 36x reduction in running time. The high-performing and fast PPC ad bidding infrastructure now drives 2M+ nights booked daily from search ads. The Apache Beam abstraction simplifies the onboarding of new team members, makes it easier to write and maintain pipelines, and accelerates time-to-market from a design document to go-live on production by as much as 4x.
The PPC team is planning to expand the use of the Apache Beam unified processing capabilities to combine several batch and streaming pipelines into a single pipeline.
Apache Beam as a model allows us to write business logic in a very declarative way. In the next development iterations, we are planning to combine several Ads Mutator pipelines into a single streaming pipeline.
Was this information useful?