




“Apache Beam has been the ideal solution for us. Scaling, backfilling historical data, experimenting with new ML models and new use cases… it is all very easy to do with Beam.”

“Apache Beam enabled self-service ML for our data scientists. They can plug in pieces of code, and those transformations will be automatically attached to models without any engineering involvement. Within seconds, our data science team can move from experimentation to production.”

Self-service Machine Learning Workflows and Scaling MLOps with Apache Beam
Background
Credit Karma is an American multinational personal finance company founded in 2007, now part of Intuit. With a free credit and financial management platform, Credit Karma enables financial progress for nearly 130 million members by providing them with personalized financial insights and recommendations.
Credit Karma’s data science and engineering teams use machine learning to serve members the most relevant content and offers optimized for each member’s financial profile and goals. Avneesh Pratap and Raj Katakam, senior data engineers at Credit Karma, shared how Apache Beam enabled them to build a robust, resilient and scalable data and ML infrastructure. They also shared details on how unified Apache Beam data processing reduces the gap between experimenting with new ML pipelines and deploying them to production.
Democratizing & Scaling MLOps
Before 2018, Credit Karma used a PHP-based ETL pipeline to ingest data from multiple financial services partners, perform different transformations and record the output into their own data warehouse. As the number of partners and members kept growing, the data teams at Credit Karma found it challenging to scale their MLOps. Making any changes and experimenting with new pipelines and attributes required significant engineering overhead. For instance, it took several weeks just to onboard a new partner. Their data engineering team was looking for ways to overcome performance drawbacks when ingesting data and scoring ML models, and to backfill new features within the same pipeline. In 2018, Credit Karma started designing their new data and ML platform - Vega - to keep up with the growing scale, understand members better, and increase their engagement with highly personalized offers.
Apache Beam, the industry standard for unified distributed processing, has been placed at the core of Vega.
When we started exploring Apache Beam, we found this programming model very promising. At first, we migrated just one partner [to an Apache Beam pipeline]. We were very impressed with the results and migrated to other partner pipelines right away.
With Apache Beam Dataflow runner, Credit Karma benefitted from Google Cloud Dataflow managed service to ensure increased scalability and efficiency. The Apache Beam built-in I/O connectors provide native support for a variety of sinks and sources, which has allowed Credit Karma to seamlessly integrate Beam into their ecosystem with various Google Cloud tools and services, including Pub/Sub, BigQuery, and Cloud Storage.
Credit Karma leveraged an Apache Beam kernel and Jupyter Notebook to create an exploratory environment in Vega and enable their data scientists to create new experimental data pipelines without engineering involvement.
The data scientists at Credit Karma mostly use SQL and Python to create new pipelines. Apache Beam provides powerful user-defined functions with multi-language capabilities that allow for authoring scalar or aggregate functions in Java or Scala, and invoking them in SQL queries. To democratize Scala transformations for their data science team, Credit Karma’s engineers abstracted out the UDFs, Tensorflow Transforms, and other complex transformations with numerous components - reusable and shareable “building blocks” - to create Credit Karma’s data and ML platform. Apache Beam and custom abstractions allow data scientists to operate these components when creating experimental pipelines and transformations, which can be easily reproduced in staging and production environments. Credit Karma’s data science team commits their code changes to a common GitHub repository, the pipelines are then merged into a staging environment, and combined into a production application.
The Apache Beam abstraction layer plays a crucial part in the operationalization of hypotheses and experiments into the production pipelines when it comes to working with financials and sensitive information. Apache Beam enables masking and filtering data right inside data pipelines before writing it to the data warehouse. Credit Karma uses Apache Thrift annotations to label the column metadata, Apache Beam pipelines filter specific elements from the data based on Thrift annotations before it reaches the data warehouse. Credit Karma’s data science team can use the available abstractions or write data transformations on top of them to calculate new metrics and validate the ML models without seeing the actual data.
Apache Beam helped us to ‘black-box’ the financial aspects and non-disclosable information so that teams can work with costs and financials without actually having access to all the data.
Currently, about 20 Apache Beam pipelines are running in production and over 100 experimental pipelines are on the way. Plenty of the upcoming experimental pipelines leverage Apache Beam stateful processing to compute user aggregates right inside the streaming pipelines, instead of computing them in the data warehouse. Credit Karma’s data science team is also planning to leverage Beam SQL to use SQL syntax directly within the stream processing pipeline and easily create aggregations. The Apache Beam abstraction of the execution engines and a variety of runners allow Credit Karma to test data pipeline performance with different engines on mock data, create benchmarks and compare the results of different data ecosystems to optimize performance depending on specific use cases.
Unified Stream & Batch Data Ingestion
Apache Beam enabled Credit Karma to revamp one of their most significant use cases - the data ingestion pipeline. Numerous Credit Karma partners send data about their financial products and offerings via gateways to Pub/Sub for downstream processing. The streaming Apache Beam pipeline written in Scio consumes Pub/Sub topics in real-time and works with deeply nested JSON data, flattening it to the database row format. The pipeline also structures and partitions the data, then writes the outcome into the BigQuery data warehouse for ML model training.
The Apache Beam unified programming model executes business logic for batch and streaming use cases, which allowed Credit Karma to develop one uniform pipeline. The data ingestion pipeline handles both real-time data and batched data ingestion to backfill historical data from partners into the data warehouse. Some of Credit Karma’s partners send historical data using object stores like GCS or S3, while some use Pub/Sub. Apache Beam unifies batch and stream processing by creating bounded and unbounded PCollections in the same pipeline depending on the use case. Reading from a batch object store creates a bounded PCollection. Reading from a streaming and continuously-updating Pub/Sub creates an unbounded PCollection. In case of backfilling just new features for past dates, Credit Karma’s data engineering team configures the same streaming Apache Beam pipeline to process chunks of historical data sent by partners in a batch fashion: read the entire data set once and join historical data elements with the data for a particular date, in a job of finite length.
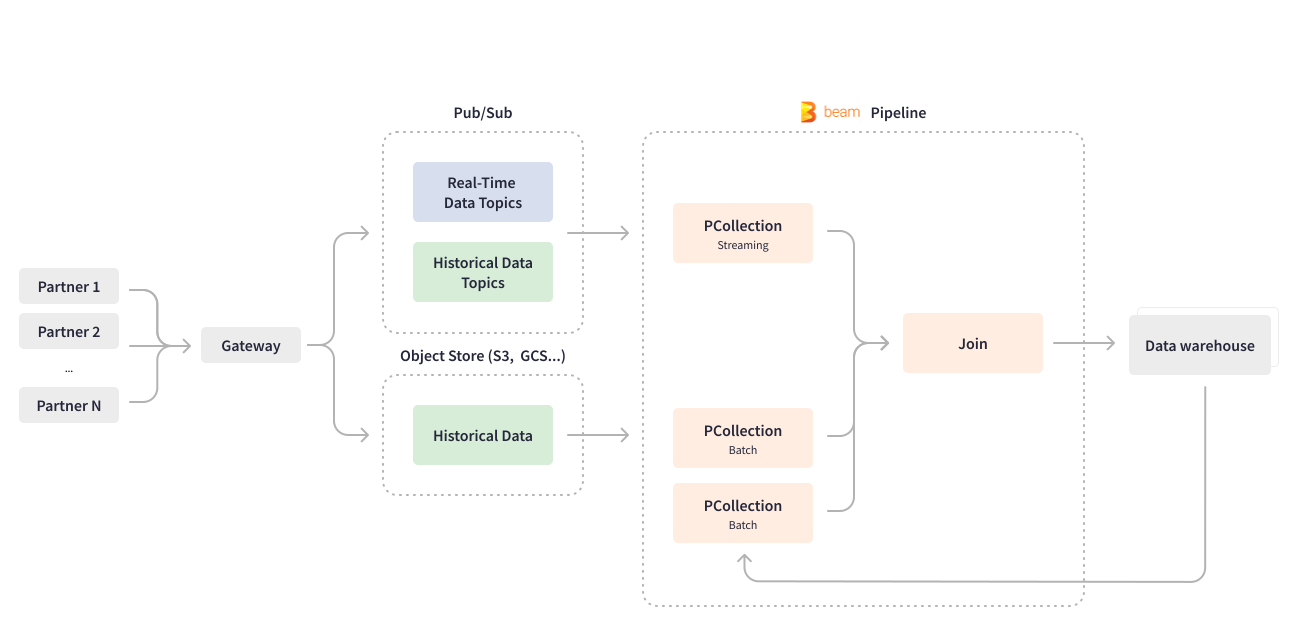
Apache Beam is flexible, its constructs allow for generic pipeline coding and ease of configuration to add new data attributes, sources and partners without changing the pipeline code. Cloud Dataflow service provides advanced features, such as dynamically replacing an ongoing streaming job with a new pipeline. The Apache Beam Dataflow runner enables Credit Karma’s data engineering team to deploy pipeline code updates without draining ongoing jobs.
Credit Karma offers a way for third-party data provider partners to deploy their own models for internal decision-making and predictions. Some of those models require custom attributes for the past 3 to 8 months to be backfilled for model training, which creates huge data spikes. The Apache Beam abstraction layer and its Dataflow runner help minimize infrastructure management efforts when dealing with these regular spikes.
With Apache Beam, you can easily add complex processing logic, for example, you can add configurable triggers on processing time. At the same time, Dataflow runner will manage execution for you, it uploads your executable code and dependencies automatically. And you have Dataflow auto-scaling working out of the box. You don’t have to worry about scaling horizontally.
Currently, the data ingestion pipeline processes and transforms more than 100 million messages, along with regular backfills, which is equivalent to around 5-10 TB worth of data.
Self-Service Machine Learning
At Credit Karma, the data scientists deal with modeling and analyzing the data, and it was crucial for the company to give them the power and flexibility to easily create, test and deploy new models. Apache Beam provided an abstraction that enabled the data scientists to write their own transformations on raw feature space for efficient ML engineering, while keeping the model serving layer independent of any custom code.
Apache Beam helped to automate Credit Karma’s machine presenting workflows, chain and score models, and prepare data for ML model training. Apache Beam provides Beam DataFrame API to identify and implement the required preprocessing steps to iterate faster towards production. Apache Beam’s built-in I/O transforms allow for reading and writing TensorFlow TFRecord files natively, and Credit Karma leverages this connectivity to preprocess data, score models, and use the model scores to recommend financial offers and content.
Apache Beam enables Credit Karma to process large volumes of data, both for preprocessing and model validation, and experiment with data during preprocessing. They use TensorFlow Transforms for applying transformations on data in batch and real-time model inferences. The output of TensorFlow Transforms is exported as a TensorFlow graph and is attached to models, making prediction services independent of any transformations. Credit Karma was able to offload ad hoc changes on prediction services by performing on-the-fly transformations on raw data, rather than aggregated data that required the involvement of their data engineering team. Their data scientists can now write any type of transformation on the raw data in SQL and deploy new models without any changes to the infrastructure.
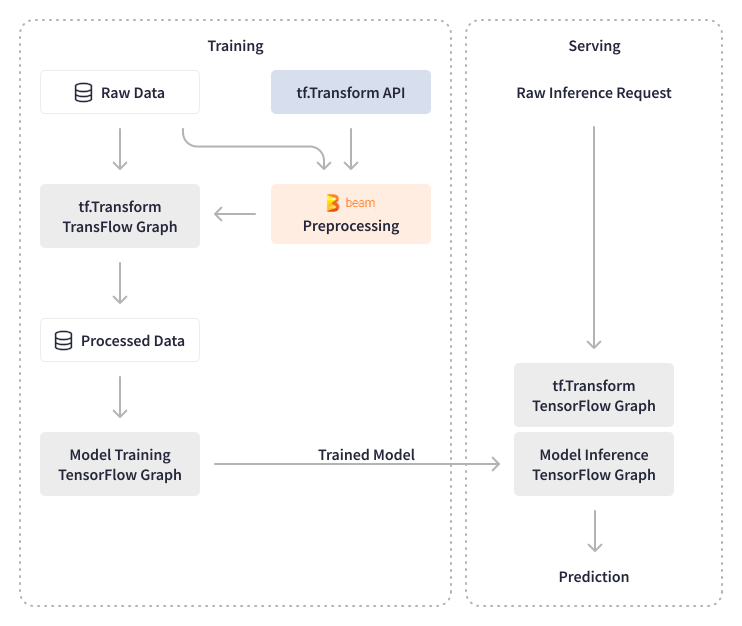
The Apache Beam and custom abstractions enable Credit Karma’s data science team to create new models, specifically for powering Credit Karma’s recommendations, without engineering overhead. The pieces of code created by data scientists are automatically compiled into an Airflow DAG, deployed to staging sandbox and then to production. On the model training and interference side, Credit Karma’s data engineers use Tensorflow libraries built on top of Apache Beam - TensorFlow Model Analysis (TFMA) and TensorFlow Data Validation (TFDV) - to perform validation of ML models and features and enable automated ML model refresh. For model analysis, they leverage native Apache Beam transforms to compute statistics and have built internal library transforms which validate new models for performance and accuracy. For instance, the batch Apache Beam pipeline calculates algorithmic features (scores) for ML models.
Apache Beam enabled self-service ML for our data scientists. They can plug in pieces of code, and those transformations will be automatically attached to models without any engineering involvement. Within seconds, our data science team can move DAGs from experimentation to production by just changing the deploy path.
Apache Beam-powered ML pipelines have proven to be incredibly reliable, processing more than 100 million events and updating ML models with fresh data daily.
Enabling Real-Time Data Availability
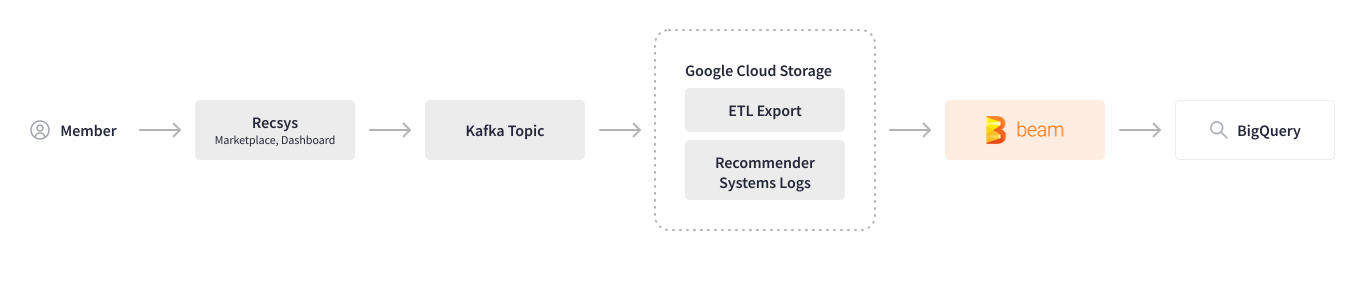
Credit Karma leverages machine learning to analyze user behavior and recommend the most relevant offers and content. Before using Apache Beam, collecting user actions (logs) across multiple systems required a myriad of manual steps and multiple tools, which resulted in processing performance drawbacks and backs-and-forths between teams whenever any changes were needed. Apache Beam helped to automate this logging pipeline. The cross-system user session logs are recorded in Kafka topics and are stored in Google Cloud Storage. The batch Apache Beam pipeline written in Scio parses the user actions for a particular tracking ID, transforms and cleans the data, and writes it to BigQuery.
Now that we have migrated the logging pipeline to Apache Beam, we are very happy with its speed and performance, and we are planning to transform this batch pipeline into a streaming one.
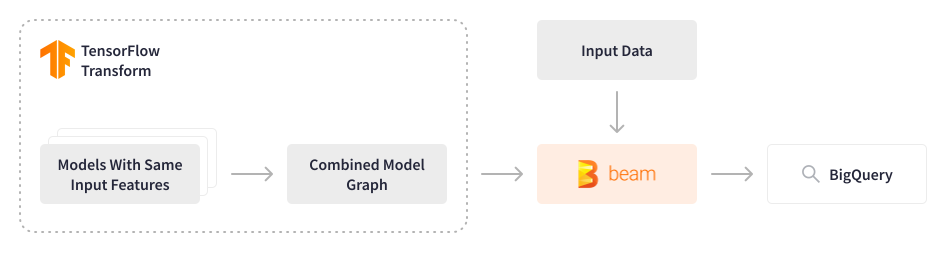
With a subset of their ML models powering recommendations and processing data for nearly 130 million members, Credit Karma employs FinOps culture to continuously explore ways to optimize infrastructure costs while increasing processing performance. Tensorflow models used in Credit Karma were historically scored sequentially one at a time, even though input features were the same, which resulted in excessive compute costs.
Apache Beam provided an opportunity to reconsider this approach. The data engineering team has developed an Apache Beam batch pipeline that combines multiple Tensorflow models into a single merged model, processes data for the last 3-9 months (~2-3 TB) at 5,000 events per second, and stores the output in the feature store. The features are then used in lightweight models for real-time predictions to recommend relevant content the very second the member logs in to the platform. This elegant solution allowed for saving compute resources and decreasing associated costs significantly, while increasing processing performance. The configuration is dynamic and allows data scientists to experiment and deploy new models seamlessly.
Results
Apache Beam has future-proofed Credit Karma’s data ecosystem for scalability and resilience, enabling them to manage over 20,000 features processed by 200 ML models, powering recommendations for nearly 130 million members daily. The scale of data processing has grown 2x since Apache Beam adoption, and their data engineering team did not have to undertake any significant changes to the infrastructure. Onboarding new partners requires minimal changes to the pipelines, compared to several weeks needed before using Apache Beam. The Apache Beam ingestion pipeline accelerated data loading to the warehouse from days to under an hour, processing around 5-10 TB of data daily. The Apache Beam batch-scoring pipeline processes historic data and generates features for lightweight ML models, enabling real-time experiences for Credit Karma members.
Apache Beam paved the way for an end-to-end data science process and efficient ML engineering at Credit Karma by abstracting the low-level details of the infrastructure and providing the data processing framework for the unified, self-service ML workflows. Credit Karma’s data scientists can now experiment with new models and have them deployed to production automatically, without the need for any engineering resources or infrastructure changes. Credit Karma presented their experience of building a self-service data and ML platform and scaling MLOps pipelines with Apache Beam at Beam Summit 2022.
Impact
These scalability initiatives enable Credit Karma to provide its members with a financial experience that is grounded in transparency, choice and personalization. Peoples’ financial situations are always in flux, as well as financial institutions’ eligibility criteria when it comes to approving consumers for financial products, especially during times of economic uncertainty. As Credit Karma continues to scale its data ecosystem, including automated model refreshes, members have peace of mind that when they use Credit Karma, they can shop for financial products with more confidence by knowing their likelihood of approval – creating a win-win scenario for both its members and partners, no matter how uncertain times are.
Learn More
Vega: Scaling MLOps Pipelines at Credit Karma using Apache Beam and Dataflow
Was this information useful?