




“Our data volume is huge and Apache Beam helps make it manageable. For each of the millions of trades per day, we generate a simulation of their market valuation evolution at granular level of future time increment, then by scanning multiple plausible market scenarios we aggregate this massive data into meaningful statistics. Apache Beam helps harness all of that data and makes data distribution much easier than before.”

“The Apache Beam Python SDK brought math to the orchestration level by providing an easy way for HSBC’s model development team to emulate sophisticated mathematical dependencies between nodes of business logic workflow in pipelines written in Python. We used to spend at least 6 months deploying even small changes to a system of equations in production. With the new team structure driven by Apache Beam, we now can deploy changes as quickly as within 1 week.”

High-Performance Quantitative Risk Analysis with Apache Beam at HSBC
Background
HSBC Holdings plc, the parent company of HSBC, is headquartered in London. HSBC serves customers worldwide from offices in 62 countries and territories. With assets of $2,990bn as of 31 March 2023, HSBC is one of the world’s largest banking and financial services organisations. HSBC’s Global Banking and Markets business provides a wide range of financial services and products to multinational corporates, governments, and financial institutions.
HSBC’s Chup Cheng, VP of XVA and CCR Capital Analytics, and Andrzej Golonka, Lead Assistant Vice President, shared how Apache Beam serves as a computation platform and a risk engine that helps HSBC manage counterparty credit risk and XVA across their customer investment portfolios, which arises from the trillions of dollars in trading volumes between numerous of counterparties every day. Apache Beam empowered HSBC to integrate their existing C++ HPC workloads into batch Apache Beam pipelines, to streamline data distribution, and to improve processing performance. Apache Beam also enabled new pipelines that were not possible before and enhanced development efficiency.
Risk Management at Scale
To realize the scale and value of the Apache Beam-powered data processing at HSBC, let us delve deeper into why Counterparty credit risk calculations at financial institutions require particularly extreme compute capacity.
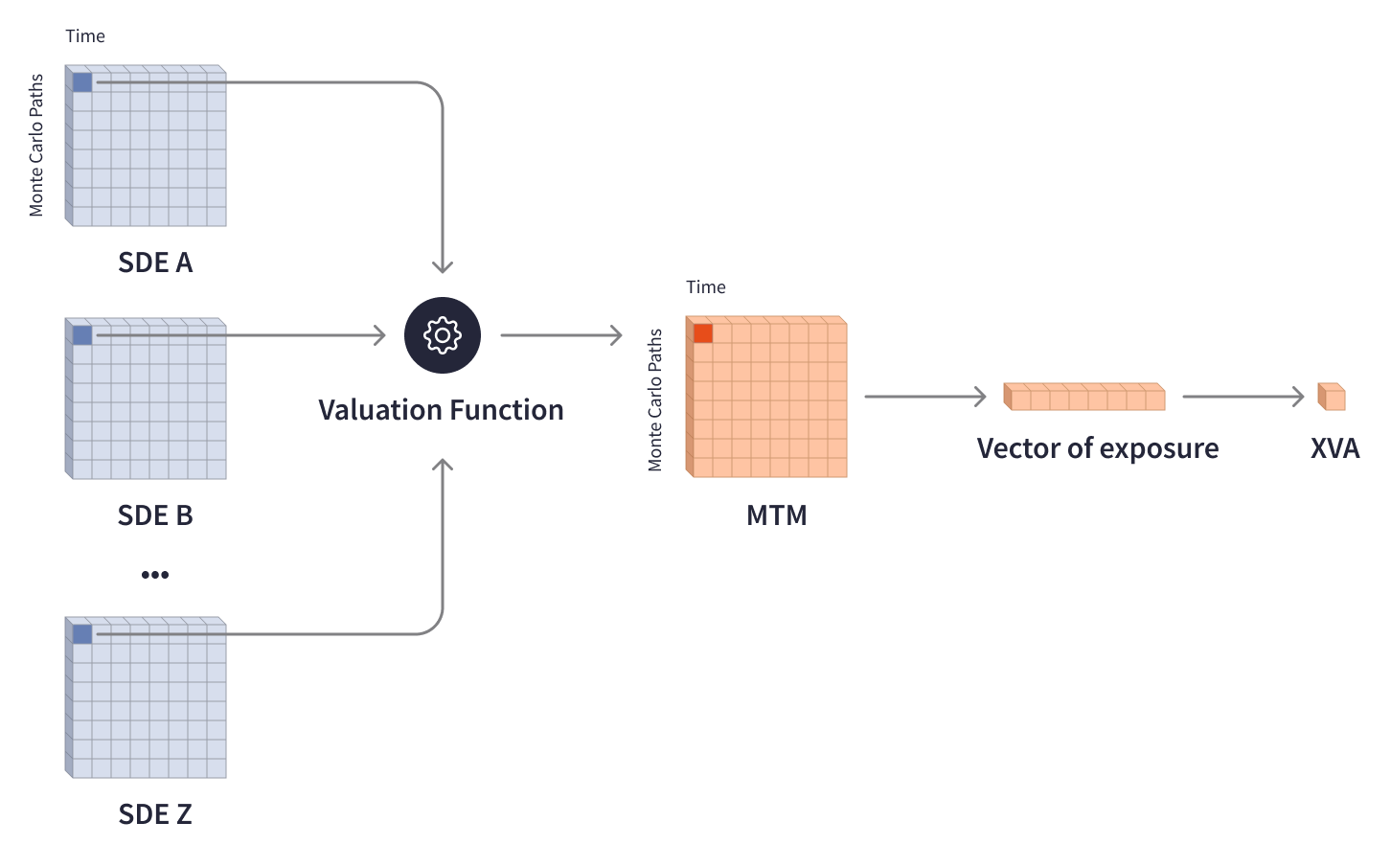
The value of an investment portfolio moves along with the financial markets and is impacted by a variety of external factors. To neutralize the risks and determine the capital reserves required by regulations, investment banks need to estimate risk exposure and make corresponding adjustments to the value of individual trades and portfolios. XVA (X-Value Adjustment) model plays a crucial role in analyzing counterparty credit risk in the financial industry and covers different valuation adjustments, such as Credit Valuation Adjustment (CVA), Funding Valuation Adjustment (FVA), and Capital Valuation Adjustment (KVA). Calculating XVA involves complex models, multi-layered matrices, and Monte Carlo simulations to account for risks based on plausible future scenarios. Valuation functions process multiple stochastic differential equation (SDE) matrices that represent probable trade values in a specific timeframe of up to possibly 70 years, and then output MTM (mark-to-market) matrices that represent the distribution of the current market value of a financial asset depending on future scenarios. Collapsed MTM matrices determine the vector of future risk exposure and the required XVA adjustment.
XVA calculations require a vast amount of computational capacity due to the extensive matrix data and long time horizons involved. To calculate MTM matrix for one trade, a valuation function needs to iterate hundreds of thousands of times through multiple SDE matrices that weigh a few megabytes and contain hundreds of thousands of elements each.
Calculating XVA on a multi-counterparties portfolio involves much more complex computations in a large system of equations. A valuation function goes through hundreds of GBs of SDE matrices, generates millions of trade-level MTM matrices, aggregates them to counterparty-level matrices, and then calculates the future exposure and XVA for each counterparty.
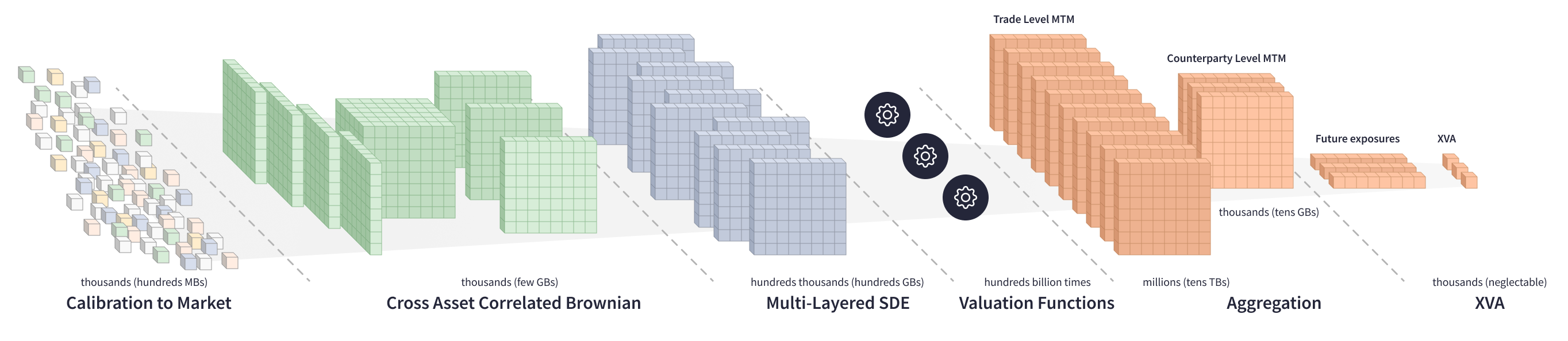
The technical challenge escalates when dealing with XVA sensitives to numerous market factors. To neutralize all market risks across counterparty portfolios, investment banks need to calculate XVA sensitivity for hundreds of market factors. There are two primary ways to compute XVA sensitivity:
- analytically through backpropagation to input
- numerically through observing how gradients move for XVA
To obtain XVA variance, a valuation function must iterate hundreds of billions of times through the enormous system of equations, which is an extremely compute-intensive process.
The XVA model is indispensable for understanding counterparty credit risk in the financial industry, and its accurate computation is vital for assessing all in price of derivatives. With an extensive amount of data and complex calculations involved, efficient and timely execution of these calculations is essential for ensuring that traders can make well-informed decisions.
Journey to Beam
NOLA is HSBC’s internal data infrastructure for XVA computations. Its previous version - NOLA1 - was an on-premise solution that used a 10 TB file server as media, processing several petabytes of data in a single batch, going through a huge network of interdependencies within each system of equations, then repeating the process. HSBC’s model development team was creating new statistical models and building the Quantitative library while their IT team was fetching the necessary data to the library, and both teams were working together to lay out orchestration between systems of equations.
The 2007 to ‘08 financial crisis highlighted the need for robust and efficient computation of XVAs across the industry, and introduced additional regulations in the financial sector that required an exponentially higher amount of computations. HSBC, therefore, sought a numerical solution for calculating the XVA sensitivities for hundreds of market factors. Processing data in a single batch had become a blocker and a throughput bottleneck. The NOLA1 infrastructure and its intensive I/O utilization was not [at the time] conducive for scaling.
HSBC engineers started looking for a new approach that would allow for scaling their data processing, maximizing throughput, and meeting critical business timelines.
Then, HSBC’s engineering team selected Apache Beam as a risk engine for NOLA for its scalability, flexibility, and ability to process large volumes of data in parallel. They found Apache Beam to be a natural process executor for the transformational, directed acyclic graphing process of XVA computations. The Apache Beam Python SDK offered a simple API to build new data pipelines in Python, while its abstraction presented a way to reuse the prevalent analytics in C++. The variety of Apache Beam runners offered portability, and HSBC’s engineers built the new version of their data infrastructure - NOLA2 - with Apache Beam pipelines running on Apache Flink and Cloud Dataflow.
Data Distribution Easier than Before
Apache Beam has greatly simplified data distribution for XVA calculations and allowed for handling the inter-correlated Monte Carlo simulations with distributed processing between workers.
The Apache Beam SDK enables users to build expressive DAGs and easily create stream or batch multi-stage pipelines in which parallel pipelined stages can be brought back together using side inputs or joins. Data movement is handled by the runner, with data expressed as PCollection objects, which are immutable parallel element collections.
Apache Beam provides several methods for distributing C++ components:
- sideloading C++ components to custom worker container images (for example, custom Apache Beam or Cloud Dataflow containers) and then using DoFns to interact with C++ components out-of-the-box
- bundling C++ with a JAR file in Apache Beam, where the C++ elements (binaries, configuration, etc.) are extracted to the local disk during the setup/teardown process in DoFn
- including the C++ components in a PCollection as a side input, which is then deployed to the local disk
The seamless integration of Apache Beam with C++ allowed HSBC’s engineers to reuse the prevalent analytics(relying on NAG and MKL libraries)and select between the logic distribution methods depending on the use case and deployment environment. HSBC found protobufs especially useful for data exchange when PCollections carry the calls and input data to the C++ libraries from Java or Python pipelines. Protobuf data can be shared over disk, network, or directly with the usage of tools like pybind11.
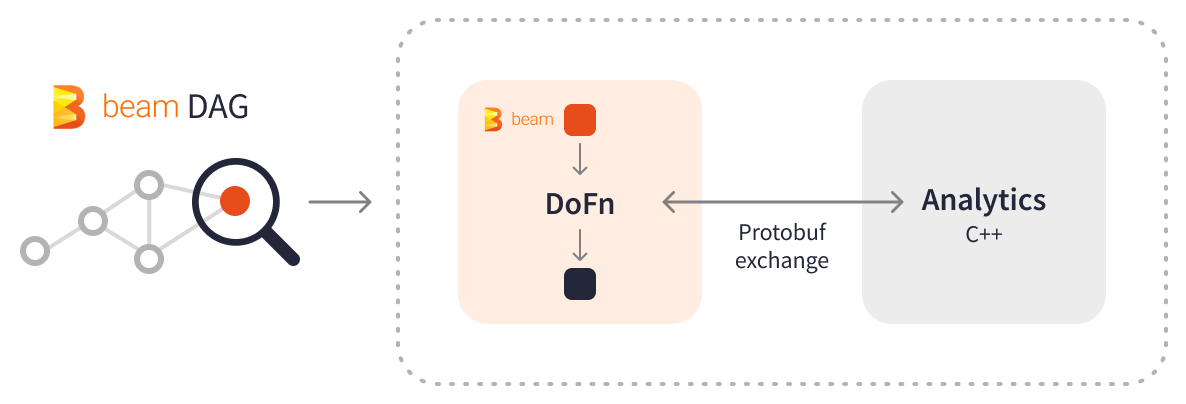
HSBC migrated their XVA calculations to a batch Apache Beam pipeline. Every day, the XVA pipeline computes over multiple thousands of billions of valuations within just 1 hour, consuming around 2 GB of external input data, processing from 10 to 20 TB of data inside the system of equations, and producing about 4 GB of output reports. Apache Beam distributes XVA calculations into a number of PCollections with tasks, performs the necessary transformations independently and in parallel, and produces map-reduced results - all in one pass.
Apache Beam provides powerful transforms and orchestration capabilities that helped HSBC engineers to optimize the analytical approach to XVA sensitivities calculation and enable the numerical one, which was not possible before. Instead of iterating a valuation function through the whole system of equations, HSBC’s engineers treat the system of equations as a computation graph, breaking it down into clusters with reusable elements and iterating through the minimal computation graph. They use Apache Beam orchestration to efficiently process tens of thousands of clusters for each portfolio by calling a C++ “executable”. Apache Beam enabled HSBC to bundle multiple market factors using KV PCollections to associate each input element of a PCollection with a key and calculate the XVA sensitivity for hundreds of market factors within a single Apache Beam batch pipeline.
The Apache Beam pipeline that performs analytical and numerical XVA sensitivities calculations runs daily in two separate batches. The first batch pipeline, which runs at midnight, determines the credit line consumption and capital utilisation for traders, directly affecting their trading volume the following day. The second batch, which completes before 8 am, calculates XVA sensitivities that could impact traders’ risk management and hedging strategies. The pipeline consumes about 2 GB of external market data daily, processing up to 400 TB of internal data in the system of equations, and aggregating the data into the output report of just about 4 GB. At the end of each month, the pipeline processes over 5 PB of monthly data inside the system of equations to produce a full-scope XVA sensitivities report. Apache Beam addresses data distribution and hot spot issues, assisting in managing the data involved in intricate calculations.
Apache Beam offers HSBC all the traits of a traditional risk engine and more, enabling HSBC to scale the infrastructure and maximize throughput with distributed processing.
Apache Beam makes data distribution much easier than before. The Monte Carlo method significantly increases the amount of data to be processed. Apache Beam helped us harness all of that data volume.
Beam as a Platform
Apache Beam is more than a data processing framework. It is also a computational platform that enables experimentation, accelerates time-to-market for new development, and simplifies deployment.
Apache Beam’s dataset abstraction as PCollection increased HSBC’s model development efficiency by providing a way to organize component ownership and reduce organizational dependencies and bottlenecks. The model development team now owns data pipelines: implements new systems of equations, defines the data transfer within a system of equations in a black box mode, and sends it to the IT team. The IT team fetches, controls, and orchestrates the external data required by a system of equations as a whole.
In general, we used to spend at least 6 months deploying even small changes to a system of equations in production. With the new team structure driven by Apache Beam, we now can deploy changes as quickly as within 1 week.
By leveraging the abstractions provided by the Apache Beam unified programming model, HSBC’s model development team can seamlessly create new data pipelines, choose an appropriate runner, and conduct experiments on Big Data without the underlying infrastructure. The Apache Beam model rules ensure the high quality of the experimental code and make it very easy to move the production-grade pipelines from experimentation to production.
With Apache Beam, it’s easy to experiment with “What if” questions. If we want to know the impact of changing some parameters, we can write a simple Apache Beam code, run the pipeline, and have the answer within minutes.
One of the key advantages of Apache Beam for Monte Carlo simulations and counterparty credit risk analysis is its ability to run the same complex simulation logic in various environments, on-premise or in the cloud, with different runners. This flexibility is especially critical in situations requiring local risk analysis in different countries and compliance zones, where sensitive financial data and information cannot be transferred beyond the local perimeter. With Apache Beam, HSBC can easily switch between runners and can future-proof their data processing for any changes. HSBC runs the majority of workflows in Cloud Dataflow, benefitting from its powerful managed service and autoscaling capabilities to manage spikes of up to 18,000 vCPUs when running batch pipelines twice a day. In select countries, they also use the Apache Beam Flink runner to comply with local regulations specific to data storage and processing.
Results
Apache Beam harnesses enormous volumes of financial market data and metrics, generates billions of trade valuations to scan plausible future scenarios reaching out around 70 years, and aggregates them into meaningful statistics, enabling HSBC to model their future scenarios and quantitatively account for risk in forecasting and decision-making.
With Apache Beam, HSBC’s engineers achieved a 2x increase in data processing performance and scaled their XVA batch pipeline by 100x compared to the original solution. The Apache Beam abstraction opened up a way to implement a numerical approach to XVA sensitivity calculation in production, which was not possible before. The batch Apache Beam pipeline calculates XVA sensitivities for hundreds of market factors, processing about 400 TB of internal data every day and up to 5 PB of data once per month.
Apache Beam portability enabled HSBC to use different runners in different regions depending on local data processing requirements and future-proof their data processing for regulatory changes.
Apache Beam provides seamless integration and out-of-the-box interaction with highly optimized computational components in C++, which saved HSBC the effort needed to rewrite the C++ analytics accumulated for years into Python.
The Apache Beam Python SDK brought math to the orchestration level by providing an easy way for HSBC’s model development team to build new Python pipelines. The new work structure driven by Apache Beam accelerated time-to-market by 24x, enabling HSBC’s teams to deploy changes and new models to production within just a few weeks.
By leveraging the versatile and scalable nature of Apache Beam for computing direct acyclic graphs that process large differential equations systems and Monte Carlo simulations, financial institutions can assess and manage counterparty credit risk efficiently, even in situations that demand localized analysis and strict compliance with data security regulations.
Learn More
Was this information useful?