




“We feel that the runner agnosticism of Apache Beam affords flexibility and future-proofs our Stream Processing Platform as new runtimes are developed. Apache Beam enabled the democratization of stream processing at Intuit and the migration of many batch jobs to streaming applications.”

Powering Streaming and Real-time ML at Intuit
Background
Intuit® is a global technology platform that provides a range of financial and marketing automation solutions, including TurboTax, QuickBooks, Mint, Credit Karma, and Mailchimp, on its mission to power prosperity around the world. Over 100 million people trust their tax preparation, small business accounting, and personal financial management to Intuit products.
Intuit developed an internal self-service Stream Processing Platform that leverages Apache Beam to accelerate time-to-market for real-time applications.
Nick Hwang, an Engineering Manager on the Intuit Data Infrastructure team, shared the story of how Apache Beam was used to build Intuit’s self-service Stream Processing Platform and provided a simple, intuitive way for developers to author, deploy, and manage streaming pipelines.
Self-service Stream Processing
When looking for AI and data-driven solutions to enhance their portfolio of financial management products, the Intuit Data Infrastructure and product teams saw an immense need for a self-service data processing platform. Their data engineers and developers needed a “paved road” to develop real-time applications while abstracting the low-level operational and infrastructure management details.
In 2019, Intuit’s Data Infrastructure team started designing their Stream Processing Platform with a mission to enable developers to focus on business logic, while the platform handles all the operational and infrastructure management details on their behalf.
The promise of our platform is that you don't have to worry about the deployment at first. You just update your code artifact, add the transformations that you want, point the pipeline to your sources and sinks, and we'll take care of the rest. You click a button and the platform will deploy your jobs for you.
Apache Beam was selected as Intuit’s Stream Processing Platform’s core data processing technology due to its flexibility to choose from a variety of programming languages and execution engines. Apache Beam’s portability and ease of adoption provided the necessary “jump-start” for the launch of the initial platform version, which used Apache Samza as an execution engine and Apache Beam streaming pipelines to read from and write to Kafka.
The primary reason why we chose Apache Beam was runner agnosticism. Our platform was a long-term investment and we wanted to be prepared for whatever may be coming eventually.
In January 2020, the first version of Intuit’s Stream Processing Platform was launched. Soon enough, the Apache Beam abstraction of the execution engines proved its benefits, allowing Intuit to seamlessly switch its data processing infrastructure from Apache Samza to Apache Flink without causing any user pain points or production downtimes.
When we decided to pivot from Apache Samza to Apache Flink, we had a couple dozen use cases and pipelines running in production, but none of the users had to change their code. The benefits of Apache Beam really showcased themselves in that case.
The Intuit Stream Processing Platform team benefitted from Apache Beam’s extensibility, which allowed them to easily wrap Apache Beam with a custom SDK layer for better interoperability with their specific Kafka installation. They paired the SDK with a graphic user interface to provide a visual way to design, manage, deploy, monitor, and debug data processing pipelines, as well as Argo Workflows to facilitate deployment on Kubernetes. The Intuit Stream Processing Platform team has also developed an internal service to help filter and manage metrics by categories when routing them to Wavefront to improve observability and monitoring of pipelines’ health. The Apache Beam in-built I/O connectors helped provide native support for a variety of sinks and sources.
The Stream Processing Platform provides developers with a full stack environment to visually design streaming pipelines; test, provision, and promote them to production; and monitor the pipelines in production. Developers create Apache Beam pipelines with the Beam Java SDK at the Stream Processing Platform’s Application Layer (see layers below). Intuit’s graphic user interface (the UX Layer) enables visual configuration of sinks and sources, compute resource scaling, pipeline lifecycle management, monitoring, and metrics. At the Control Layer, the Spring-based backend maintains metadata on all pipelines running on the platform and interacts with the Intuit ecosystem for data governance, asset management, and data lineage. The UX Layer communicates with the Control Layer, which invokes Argo Workflows to deploy Apache Beam pipelines upon an Apache Flink runtime layer hosted on Kubernetes.
With the promise of an out-of-the-box solution, Intuit’s Stream Processing Platform has been designed to allow reusable templated implementations to accelerate the development of common use cases, while still providing the ability to customize for standalone applications. For instance, Intuit created its own DSL interface to provide custom configurations for simple transformations of the clickstream topics.
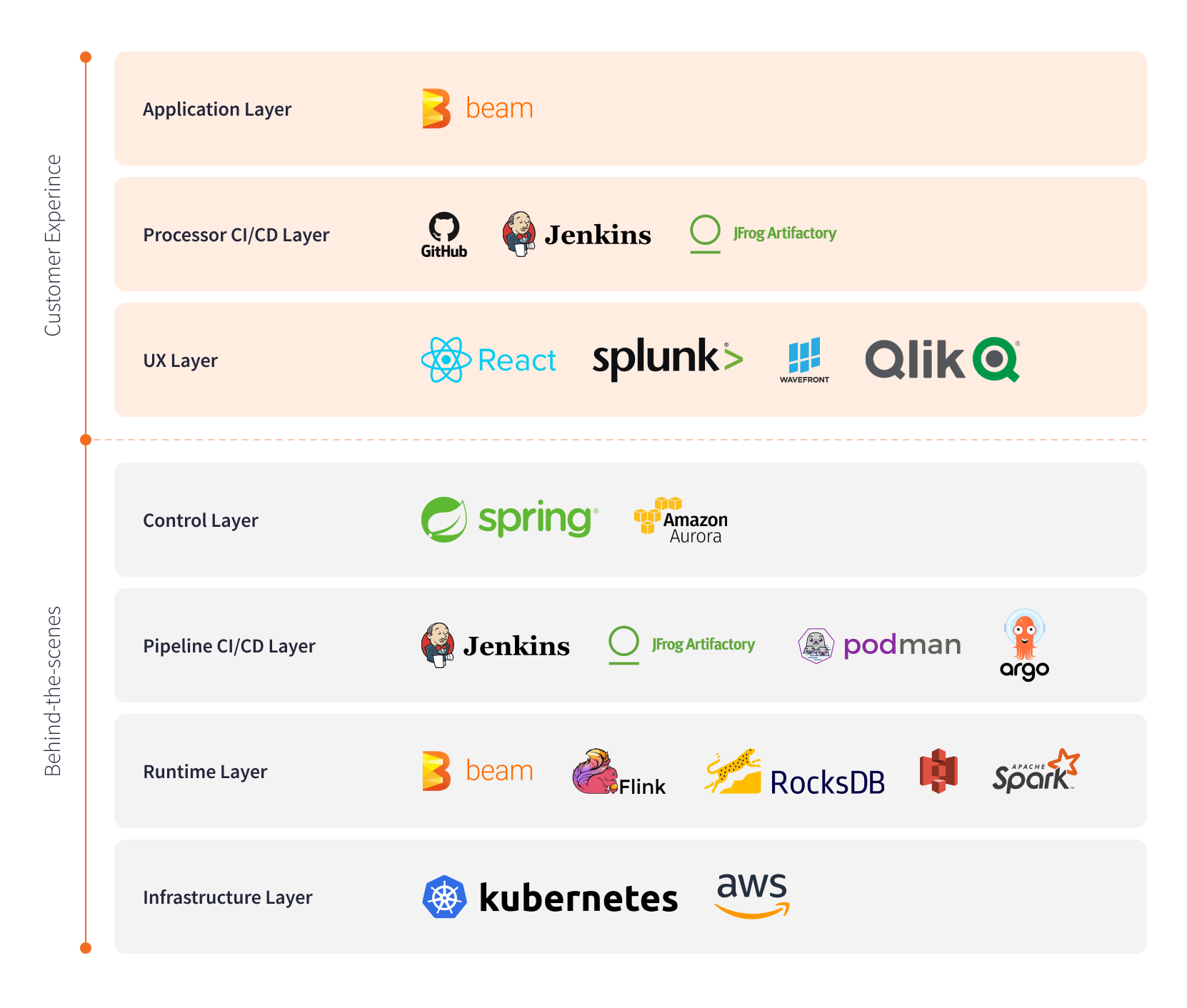 Intuit Stream Processing Platform’s Tech Stack
Intuit Stream Processing Platform’s Tech StackThe platform empowered much easier adoption of stream processing, providing self-service capabilities for Intuit’s data engineers and developers.
The whole idea of our platform is to minimize the barrier to entry to get your real-time application up and running. Like, “I just want to run this SQL query on a Kafka topic and write it to some sink, tell me how to do that in a day and not two months.
Powering Real-time Data
Apache Beam-powered unified clickstream processing is the most impactful of Intuit’s use cases. The Apache Beam streaming pipeline consumes, aggregates, and processes raw clickstream events, such as website visits, from Kafka across the large portfolio of Intuit’s products. The clickstream pipeline enriches the data with geolocation along with other new features, sessionizes and standardizes it for writing to Kafka and use by downstream applications, processing over 60,000 transactions per second. The Intuit Data Infrastructure team realizes the value of Apache Beam composite transforms, such as windowing, timers, and stateful processing for fine-grained control over data freshness. Apache Beam stream processing allows Intuit to enrich clickstream data with new features every 1 minute instead of every 4 hours, improving the availability of real-time data by 240x, and reduce costs associated with memory and compute resources by 5x.
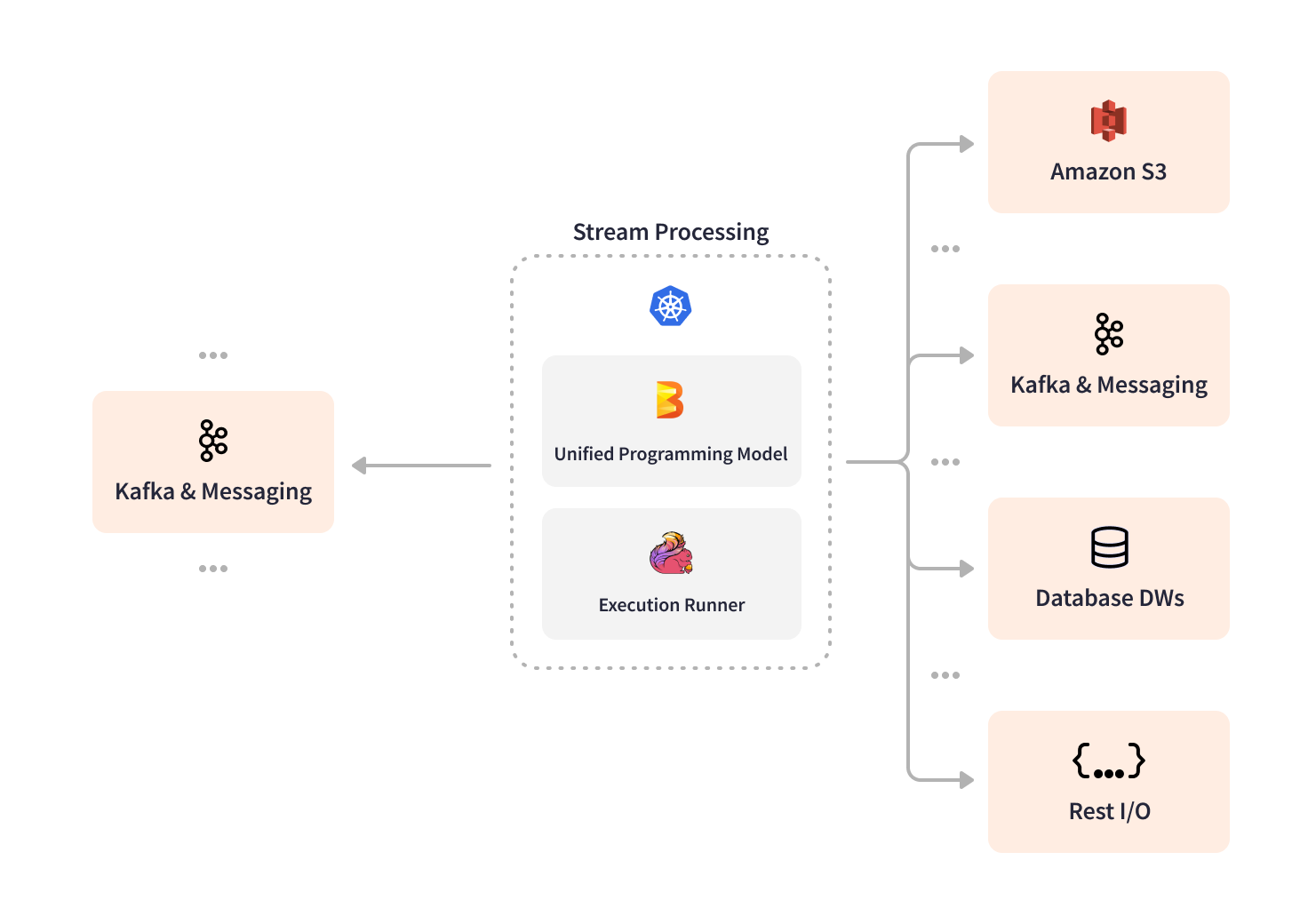 Intuit Stream Processing Platform’s Pipeline Topology
Intuit Stream Processing Platform’s Pipeline TopologyAnother front-and-center Apache Beam use case from Intuit’s business perspective is the feature store ingestion platform that enables new AI and ML-powered customer experiences. Several Apache Beam pipelines take in real-time features generated by other Apache Beam pipelines on the platform from Kafka and write them to the Intuit feature store for ML model training and inference. Pipelines generating real-time features can also use a capability offered by the platform to “backfill” features when historic data needs to be re-featurized, even if the features are stateful. The same stream processing code will first read Intuit’s historic data from the data lake, reprocess the data to bootstrap the pipeline’s state, then switch to a streaming context that uses the bootstrapped state. This is all done in a way that abstracts the complexity of the backfill process from the machine learning engineer or data scientist owning the pipeline.
Results
Since Intuit Stream Processing Platform’s launch, the number of Apache Beam-powered streaming pipelines has been growing 2x per year and as of July’22 reached over 160 active production pipelines running on 710 nodes across 6 different Kubernetes clusters. The Apache Beam pipelines handle ~17.3 billion events and 82 TB of data, processing 800,000 transactions per second at peak seasons.
Apache Beam and its abstraction of the execution engines allowed Intuit to seamlessly switch their primary runner without rewriting the code to a new execution environment runner. It also provided confidence by future-proofing the Intuit Stream Processing Platform for flexibility as new execution runtimes keep evolving. Apache Beam helped lower the entry barrier, democratize stream processing across Intuit’s development teams, and ensure fast onboarding for engineers without prior experience with Apache Flink or other streaming data processing tools. Apache Beam facilitated the migration from batch jobs to streaming applications, enabling new real-time and ML-powered experiences for Intuit customers.
With Apache Beam, Intuit accelerated the development and launch of production-grade streaming data pipelines 3x, from 3 months to just 1 month. The time to design pipelines for preproduction shrank to just 10 days. Migration from batch jobs to Apache Beam streaming pipelines resulted in a 5x memory and compute cost optimization. Intuit continues developing Apache Beam streaming pipelines for new use cases, 150 more pipelines are in preproduction and coming to production soon.
Learn More
Was this information useful?