




“Apache Beam empowers LinkedIn to create timely recommendations and personalized experiences by leveraging the freshest data and processing it in real-time, ultimately benefiting LinkedIn's vast network of over 950 million members worldwide.”

Revolutionizing Real-Time Stream Processing: 4 Trillion Events Daily at LinkedIn
Background
At LinkedIn, Apache Beam plays a pivotal role in stream processing infrastructures that process over 4 trillion events daily through more than 3,000 pipelines across multiple production data centers. This robust framework empowers near real-time data processing for critical services and platforms, ranging from machine learning and notifications to anti-abuse AI modeling. With over 950 million members, ensuring that our platform is running smoothly is critical to connecting members to opportunities worldwide.
In this case study, LinkedIn’s Bingfeng Xia, Engineering Manager, and Xinyu Liu, Senior Staff Engineer, shed light on how the Apache Beam programming model’s unified, portable, and user-friendly data processing framework has enabled a multitude of sophisticated use cases and revolutionized Stream Processing at LinkedIn. This technology has optimized cost-to-serve by 2x by unifying stream and batch processing through Apache Samza and Apache Spark runners, enabled real-time ML feature generation, reduced time-to-production for new pipelines from months to days, allowed for processing time-series events at over 3 million queries per second, and more. For our members, this means that we’re able to serve more accurate job recommendations, improve feed recommendations, and identify fake profiles at a faster rate, etc.
LinkedIn Open-Source Ecosystem and Journey to Beam
LinkedIn has a rich history of actively contributing to the open-source community, demonstrating its commitment by creating, managing, and utilizing various open-source software projects. The LinkedIn engineering team has open-sourced over 75 projects across multiple categories, with several gaining widespread adoption and becoming part of the Apache Software Foundation.
To enable the ingestion and real-time processing of enormous volumes of data, LinkedIn built a custom stream processing ecosystem largely with tools developed in-house (and subsequently open-sourced). In 2010, they introduced Apache Kafka, a pivotal Big Data ingestion backbone for LinkedIn’s real-time infrastructure. To transition from batch-oriented processing and respond to Kafka events within minutes or seconds, they built an in-house distributed event streaming framework, Apache Samza. This framework, along with Apache Spark for batch processing, formed the basis of LinkedIn’s lambda architecture for data processing jobs. Over time, LinkedIn’s engineering team expanded the stream processing ecosystem with more proprietary tools like Brooklin, facilitating data streaming across multiple stores and messaging systems, and Venice, serving as a storage system for ingesting batch and stream processing job outputs, among others.
Though the stream processing ecosystem with Apache Samza at its core enabled large-scale stateful data processing, LinkedIn’s ever-evolving demands required higher scalability and efficiency, as well as lower latency for the streaming pipelines. The lambda architecture approach led to operational complexity and inefficiencies, because it required maintaining two different codebases and two different engines for batch and streaming data. To address these challenges, data engineers sought a higher level of stream processing abstraction and out-of-the-box support for advanced aggregations and transformations. Additionally, they needed the ability to experiment with streaming pipelines in batch mode. There was also a growing need for multi-language support within the overall Java-prevalent teams due to emerging machine learning use cases requiring Python.
The release of Apache Beam in 2016 proved to be a game-changer for LinkedIn. Apache Beam offers an open-source, advanced unified programming model for both batch and Stream Processing, making it possible to create a large-scale common data infrastructure across various applications. With support for Python, Go, and Java SDKs and a rich, versatile API layer, Apache Beam provided the ideal solution for building sophisticated multi-language pipelines and running them on any engine.
When we started looking at Apache Beam, we realized it was a very attractive data processing framework for LinkedIn’s demands: not only does it provide an advanced API, but it also allows for converging stream and batch processing and multi-language support. Everything we were looking for and out-of-the-box.

Recognizing the advantages of Apache Beam’s unified data processing API, advanced capabilities, and multi-language support, LinkedIn began onboarding its first use cases and developed the Apache Samza runner for Beam in 2018. By 2019, Apache Beam pipelines were powering several critical use cases, and the programming model and framework saw extensive adoption across LinkedIn teams. Xinyu Liu showcased the benefits of migrating to Apache Beam pipelines during Beam Summit Europe 2019.
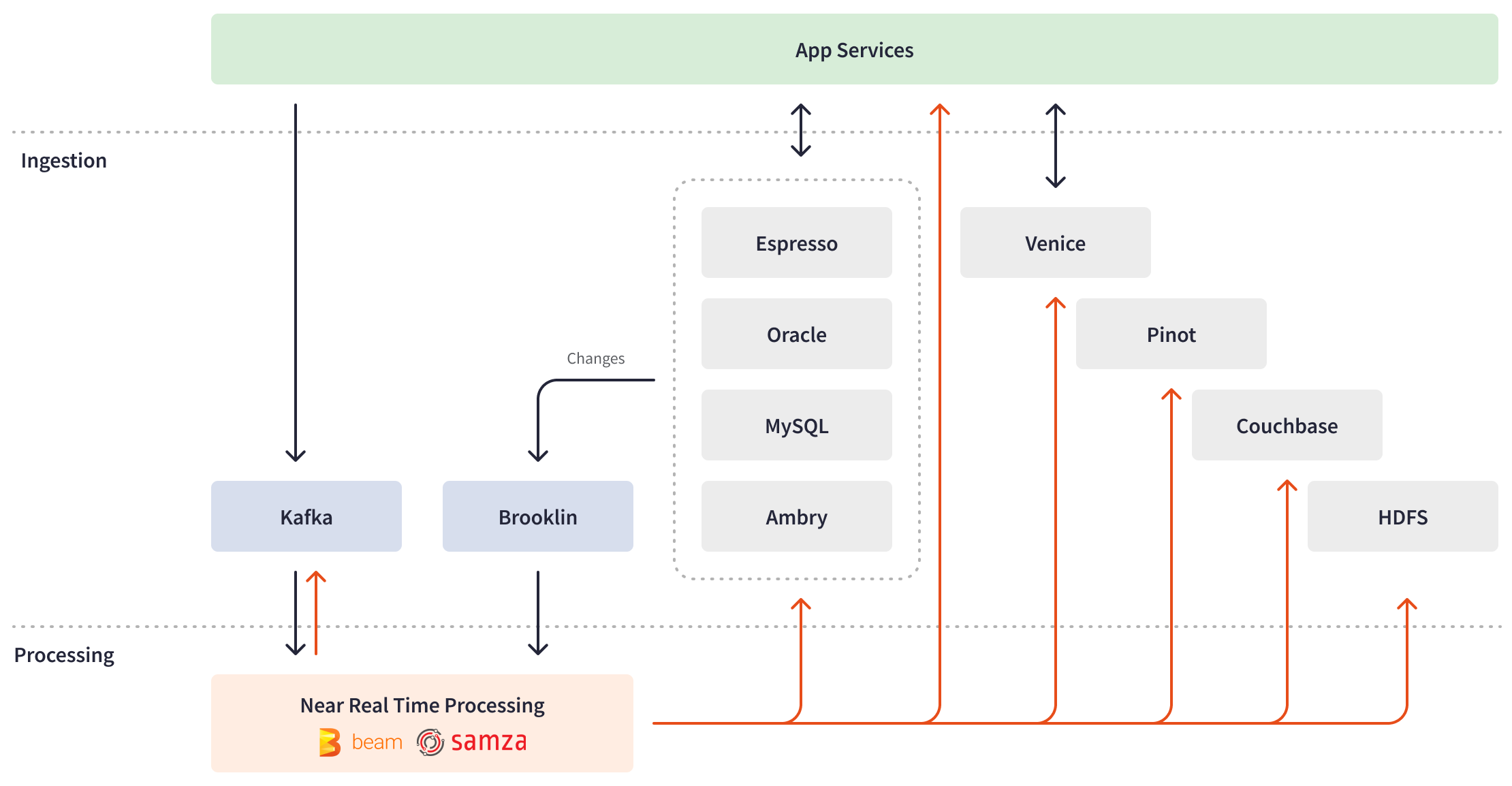
Apache Beam Use Cases at LinkedIn
Unified Streaming And Batch Pipelines
Some of the first use cases that LinkedIn migrated to Apache Beam pipelines involved both real-time computations and periodic backfilling. One example was LinkedIn’s standardization process. Standardization consists of a series of pipelines that use complex AI models to map LinkedIn user inputs, such as job titles, skills, or education history, into predefined internal IDs. For example, a LinkedIn member who lists their current position as “Chief Data Scientist” has their job title standardized for relevant job recommendations.
LinkedIn’s standardization process requires both real-time processing to reflect immediate user updates and periodic backfilling to refresh data when new AI models are introduced. Before adopting Apache Beam, running backfilling as a streaming job required over 5,000 GB-hours in memory and nearly 4,000 hours in total CPU time. This heavy load led to extended backfilling times and scaling issues, causing the backfilling pipeline to act as a “noisy neighbor” to colocated streaming pipelines and failing to meet latency and throughput requirements. Although LinkedIn engineers considered migrating the backfilling logic to a batch Spark pipeline, they abandoned the idea due to the unnecessary overhead of maintaining two different codebases.
We came to the question: is it possible to only maintain one codebase but with the ability to run it as either a batch job or streaming job? The unified Apache Beam model was the solution.
The Apache Beam APIs enabled LinkedIn engineers to implement business logic once within a unified Apache Beam pipeline that efficiently handles both real-time standardization and backfilling. Apache Beam offers PipelineOptions, enabling the configuration and customization of various aspects, such as the pipeline runner and runner-specific configurations. The extensibility of Apache Beam transforms allowed LinkedIn to create a custom composite transform to abstract away I/O differences and switch target processing on the fly based on data source type (bounded or unbounded). In addition, Apache Beam’s abstraction of the underlying infrastructure and the ability to “write once, run anywhere” empowered LinkedIn to seamlessly switch between data processing engines. Depending on the target processing type, streaming, or batch, the unified Apache Beam standardization pipeline can be deployed through the Samza cluster as a streaming job or through the Spark cluster as a batch backfilling job.
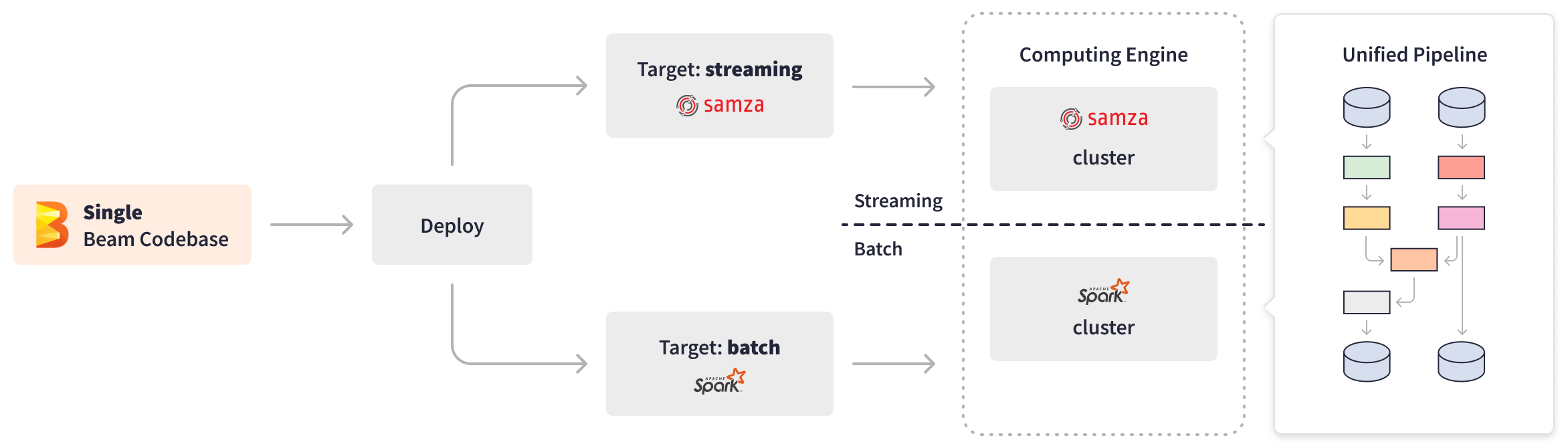
Hundreds of streaming Apache Beam jobs now power real-time standardization, listening to events 24/7, enriching streams with additional data from remote tables, performing necessary processing, and writing results to output databases. The batch Apache Beam backfilling job runs weekly, effectively handling 950 million member profiles at a rate of over 40,000 profiles per second. Apache Beam infers data points into sophisticated AI and machine learning models and joins complex data such as job types and work experiences, thus standardizing user data for search indexing or to run recommendation models.
The migration of backfilling logic to a unified Apache Beam pipeline and its execution in batch mode resulted in a significant 50% improvement in memory and CPU usage efficiency (from ~5000 GB-hours and ~4000 CPU hours to ~2000 GB-hours and ~1700 CPU hours) and an impressive 94% acceleration in processing time (from 7.5 hours to 25 minutes). More details about this use case can be found on LinkedIn’s engineering blog.
Anti-Abuse & Near Real-Time AI Modeling
LinkedIn is firmly committed to creating a trusted environment for its members, and this dedication extends to safeguarding against various types of abuse on the platform. To achieve this, the Anti-Abuse AI Team at LinkedIn plays a crucial role in creating, deploying, and maintaining AI and deep learning models that can detect and prevent different forms of abuse, such as fake account creation, member profile scraping, automated spam, and account takeovers.
Apache Beam fortifies LinkedIn’s internal anti-abuse platform, Chronos, enabling abuse detection and prevention in near real-time. Chronos relies on two streaming Apache Beam pipelines: the Filter pipeline and the Model pipeline. The Filter pipeline reads user activity events from Kafka, extracts relevant fields, aggregates and filters the events, and then generates filtered Kafka messages for downstream AI processing. Subsequently, the Model pipeline consumes these filtered messages, aggregates member activity within specific time windows, triggers AI scoring models, and writes the resulting abuse scores to various internal applications, services, and stores for offline processing.
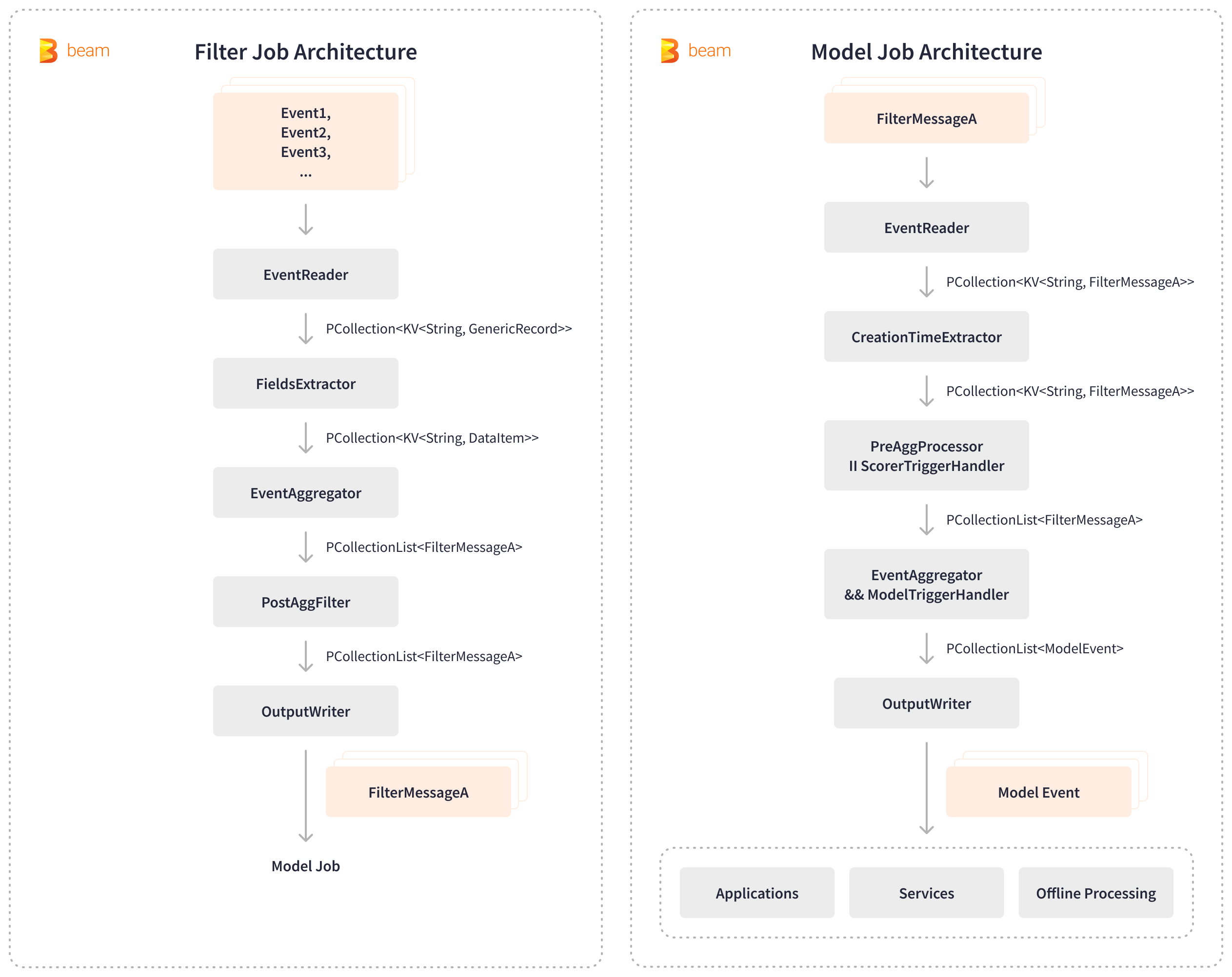
The flexibility of Apache Beam’s pluggable architecture and the availability of various I/O options seamlessly integrated the anti-abuse pipelines with Kafka and key-value stores. LinkedIn has dramatically reduced the time it takes to label abusive actions, cutting it down from 1 day to just 5 minutes and processing time-series events at an impressive rate of over 3 million queries per second. Apache Beam empowered near real-time processing, significantly bolstering LinkedIn’s anti-abuse defenses. The nearline defenses are able to catch scrapers within minutes after they start to scrape and this leads to more than 6% improvement in detecting logged-in scrapping profiles.
Apache Beam enabled revolutionary, phenomenal performance improvements - the anti-abuse processing accelerated from 1 day to 5 minutes. We have seen more than 6% improvement in detecting logged-in scrapping profiles.
Notifications Platform
As a social media network, LinkedIn heavily relies on instant notifications to drive member engagement. To achieve this, Apache Beam and Apache Samza together power LinkedIn’s large-scale Notifications Platform that generates notification content, pinpoints the target audience, and ensures the timely and relevant distribution of content.
The streaming Apache Beam pipelines have intricate business logic and handle enormous volumes of data in a near real-time fashion. The pipelines consume, aggregate, partition, and process events from over 950 million LinkedIn members and feed the data to downstream machine learning models. The ML models perform distributed targeting and scalable scoring on the order of millions of candidate notifications per second based on the recipient member’s historical actions and make personalized decisions for the recipient for each notification on the fly. As a result, LinkedIn members receive timely, relevant, and actionable activity-based notifications, such as connection invites, job recommendations, daily news digests, and other activities within their social network, through the right channels.
The advanced Apache Beam API offers complex aggregation and filtering capabilities out-of-the-box, and its programming model allows for the creation of reusable components. These features enable LinkedIn to expedite development and streamline the scaling of the Notifications platform as they transition more notification use cases from Samza to Beam pipelines.
LinkedIn’s user engagement is greatly driven by how timely we can send relevant notifications. Apache Beam enabled a scalable, near real-time infrastructure behind this business-critical use case.
Real-Time ML Feature Generation
LinkedIn’s core functionalities, such as job recommendations and search feed, heavily rely on ML models that consume thousands of features related to various entities like companies, job postings, and members. However, before the adoption of Apache Beam, the original offline ML feature generation pipeline suffered from a delay of 24 to 48 hours between member actions and the impact of those actions on the recommendation system. This delay resulted in missed opportunities, because the system lacked sufficient data about infrequent members and failed to capture the short-term intent and preferences of frequent members. In response to the growing demand for a scalable, real-time ML feature generation platform, LinkedIn turned to Apache Beam to address the challenge.
Using Managed Beam as the foundation, LinkedIn developed a hosted platform for ML feature generation. The ML platform provides AI engineers with real-time features and an efficient pipeline authoring experience, all while abstracting away deployment and operational complexities. AI engineers create feature definitions and deploy them using Managed Beam. When LinkedIn members take actions on the platform, the streaming Apache Beam pipeline generates fresher machine learning features by filtering, processing, and aggregating the events emitted to Kafka in real-time and writes them to the feature store. Additionally, LinkedIn introduced other Apache Beam pipelines responsible for retrieving the data from the feature store, processing it, and feeding it into the recommendation system.
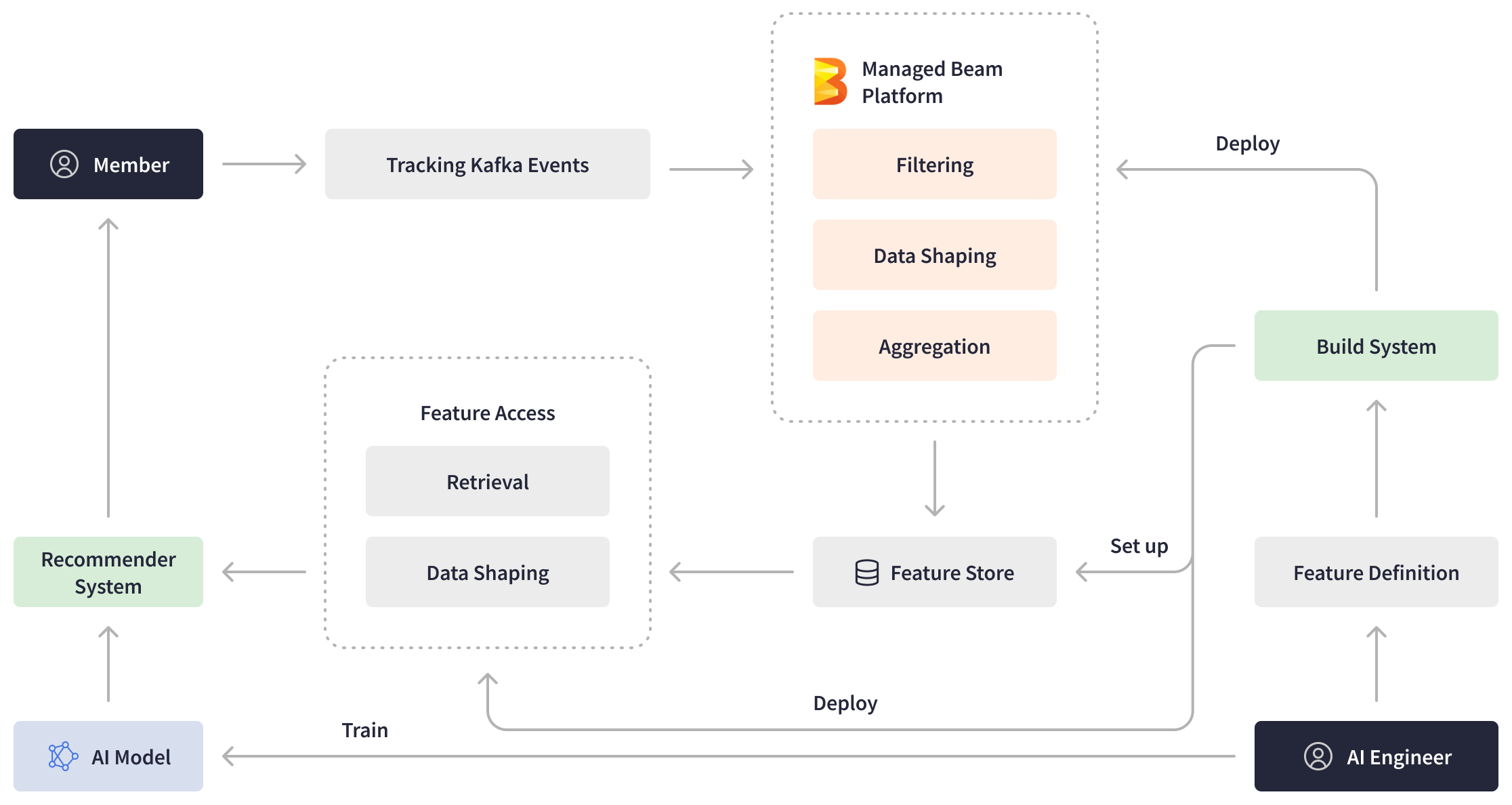
The powerful Apache Beam Stream Processing platform played a pivotal role in eliminating the delay between member actions and data availability, achieving an impressive end-to-end pipeline latency of just a few seconds. This significant improvement allowed LinkedIn’s ML models to take advantage of up-to-date information and deliver more personalized and timely recommendations to our members, leading to significant gains in business metrics.
Managed Stream Processing Platform
As LinkedIn’s data infrastructure grew to encompass over 3,000 Apache Beam pipelines, catering to a diverse range of business use cases, LinkedIn’s AI and data engineering teams found themselves overwhelmed with managing these streaming applications 24/7. The AI engineers encountered several technical challenges while creating new pipelines, including the intricacy of integrating multiple streaming tools and infrastructures into their frameworks, and limited knowledge of the underlying infrastructure when it came to deployment, monitoring, and operations. These challenges led to a time-consuming pipeline development cycle, often lasting one to two months. Apache Beam enabled LinkedIn to create Managed Beam, a managed Stream Processing platform that is designed to streamline and automate internal processes. This platform makes it easier and faster for teams to develop and operate sophisticated streaming applications while reducing the burden of on-call support.
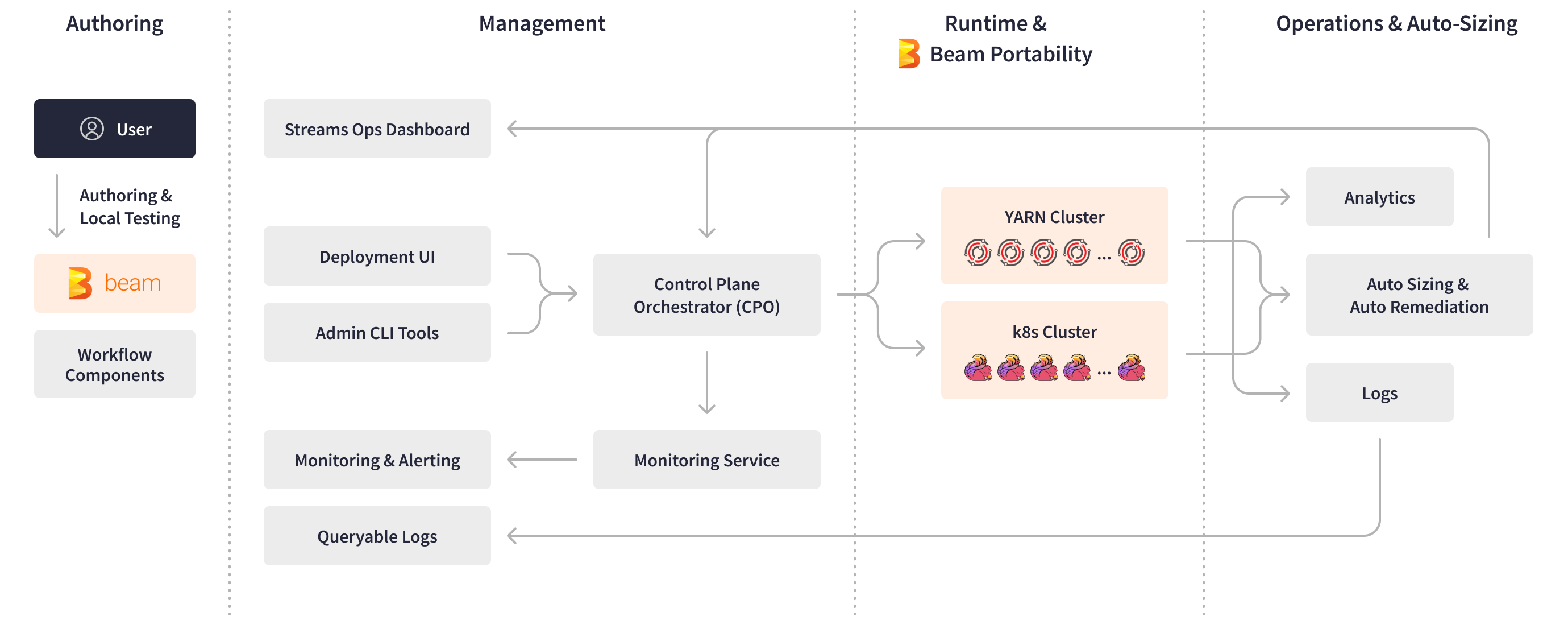
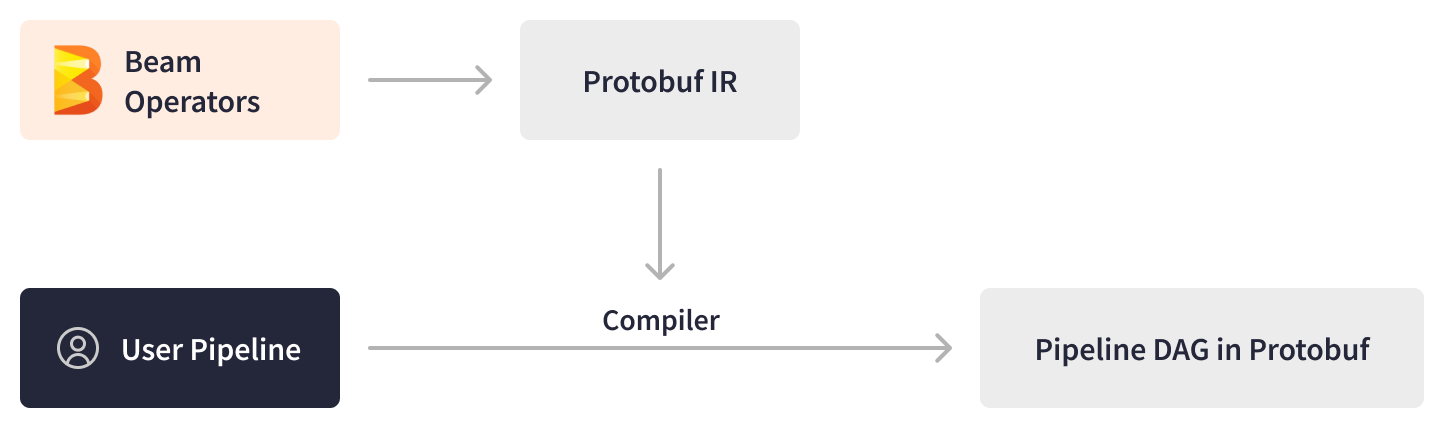
The Apache Beam SDK empowered LinkedIn engineers to create custom workflow components as reusable sub-DAGs (Directed Acyclic Graphs) and expose them as standard PTransforms. These PTransforms serve as ready-to-use building blocks for new pipelines, significantly speeding up the authoring and testing process for LinkedIn AI engineers. By abstracting the low-level details of underlying engines and runtime environments, Apache Beam allows engineers to focus solely on business logic, further accelerating time to development.
When the pipelines are ready for deployment, Managed Beam’s central control plane comes into play, providing essential features like a deployment UI, operational dashboard, administrative tools, and automated pipeline lifecycle management.
Apache Beam’s abstraction facilitated the isolation of user code from framework evolution during build, deployment, and runtime. To ensure the separation of runner processes from user-defined functions (UDFs), Managed Beam packages the pipeline business logic and the framework logic as two separate JAR files: framework-less artifacts and framework artifacts. During pipeline execution on a YARN cluster, these pipeline artifacts run in a Samza container as two distinct processes, communicating through gRPC. This setup enabled LinkedIn to take advantage of automated framework upgrades, scalable UDF execution, log separation for easier troubleshooting, and multi-language APIs, fostering flexibility and efficiency.
Apache Beam also underpinned Managed Beam’s autosizing controller tool, which automates hardware resource tuning and provides auto-remediation for streaming pipelines. Streaming Apache Beam pipelines self-report diagnostic information, such as metrics and key deployment logs, in the form of Kafka topics. Additionally, LinkedIn’s internal monitoring tools report runtime errors, such as heartbeat failures, out-of-memory events, and processing lags. The Apache Beam diagnostics processor pipeline aggregates, repartitions, and windows these diagnostic events before passing them to the autosizing controller and writing them to Apache Pinot, LinkedIn’s OLAP store for Managed Beam’s operational and analytics dashboards. Based on the pre-processed and time-windowed diagnostic data, the autosizing controller generates sizing actions or restarting actions, and then forwards them to the Managed Beam control plane. The Managed Beam control plane then scales LinkedIn’s streaming applications and clusters.
Apache Beam helped streamline operations management and enabled fully-automated autoscaling, significantly reducing the time to onboard new applications. Previously, onboarding required a lot of manual 'trial and error' iterations and deep knowledge of the internal system and metrics.
The extensibility, pluggability, portability, and abstraction of Apache Beam formed the backbone of LinkedIn’s Managed Beam platform. The Managed Beam platform accelerated the time to author, test, and stabilize streaming pipelines from months to days, facilitated fast experimentation, and almost entirely eliminated operational costs for AI engineers.
Summary
Apache Beam played a pivotal role in revolutionizing and scaling LinkedIn’s data infrastructure. Beam’s powerful streaming capabilities enable real-time processing for critical business use cases, at a scale of over 4 trillion events daily through more than 3,000 pipelines.
The versatility of Apache Beam empowered LinkedIn’s engineering teams to optimize their data processing for various business use cases:
- Apache Beam’s unified and portable framework allowed LinkedIn to consolidate streaming and batch processing into unified pipelines. These unified pipelines resulted in a 2x optimization in cost-to-serve, a 2x improvement in processing performance, and a 2x improvement in memory and CPU usage efficiency.
- LinkedIn’s anti-abuse platform leveraged Apache Beam to process user activity events from Kafka in near-real-time, achieving a remarkable acceleration from days to minutes in labeling abusive actions. The nearline defenses are able to catch scrapers within minutes after they start to scrape and this leads to more than 6% improvement in detecting logged-in scrapping profiles.
- By adopting Apache Beam, LinkedIn was able to transition from an offline ML feature generation pipeline with a 24- to 48-hour delay to a real-time platform with an end-to-end pipeline latency at the millisecond or second level.
- Apache Beam’s abstraction and powerful programming model enabled LinkedIn to create a fully managed stream processing platform, thus facilitating easier authoring, testing, and deployment and accelerating time-to-production for new pipelines from months to days.
Apache Beam boasts seamless plug-and-play capabilities, integrating smoothly with Apache Kafka, Apache Pinot, and other core technologies at LinkedIn, all while ensuring optimal performance at scale. As LinkedIn continues experimenting with new engines and tooling, the Apache Beam portability future-proofs our ecosystem against any changes in the underlying infrastructure.
By enabling a scalable, near real-time infrastructure behind business-critical use cases, Apache Beam empowers LinkedIn to leverage the freshest data and process it in real-time to create timely recommendations and personalized experiences, ultimately benefiting LinkedIn's vast network of over 950 million members worldwide.
Was this information useful?