




“I know one thing: Beam is very powerful and the abstraction is its most significant feature. With the right abstraction we have the flexibility to run workloads where needed. Thanks to Beam, we are not locked to any vendor, and we don’t need to change anything else if we make the switch.”

Real-time Event Stream Processing at Scale for Palo Alto Networks
Background
Palo Alto Networks, Inc. is a global cybersecurity leader with a comprehensive portfolio of enterprise products. Palo Alto Networks protects and provides visibility, trusted intelligence, automation, and flexibility to over 85K customers across clouds, networks, and devices.
Palo Alto Networks’ integrated security operations platform - Cortex™ - applies AI and machine learning to enable security automation, advanced threat intelligence, and effective rapid security responses for Palo Alto Networks’ customers. Cortex™ Data Lake infrastructure collects, integrates, and normalizes enterprises’ security data combined with trillions of multi-source artifacts.
Cortex™ data infrastructure processes ~10 millions of security log events per second currently, at ~3 PB per day, which are on the high end of real-time streaming processing scale in the industry. Palo Alto Networks’ Sr Principal Software Engineer, Talat Uyarer, shared insights on how Apache Beam provides a high-performing, reliable, and resilient data processing framework to support this scale.
Large-scale Streaming Infrastructure
When building the data infrastructure from the ground up, Palo Alto Networks’ Cortex Data Lake team faced a challenging task. We needed to ensure that the Cortex platform could stream and process petabyte-sized data coming from customers’ firewalls, networks, and all kinds of devices to customers and internal apps with low latency and perfect quality.
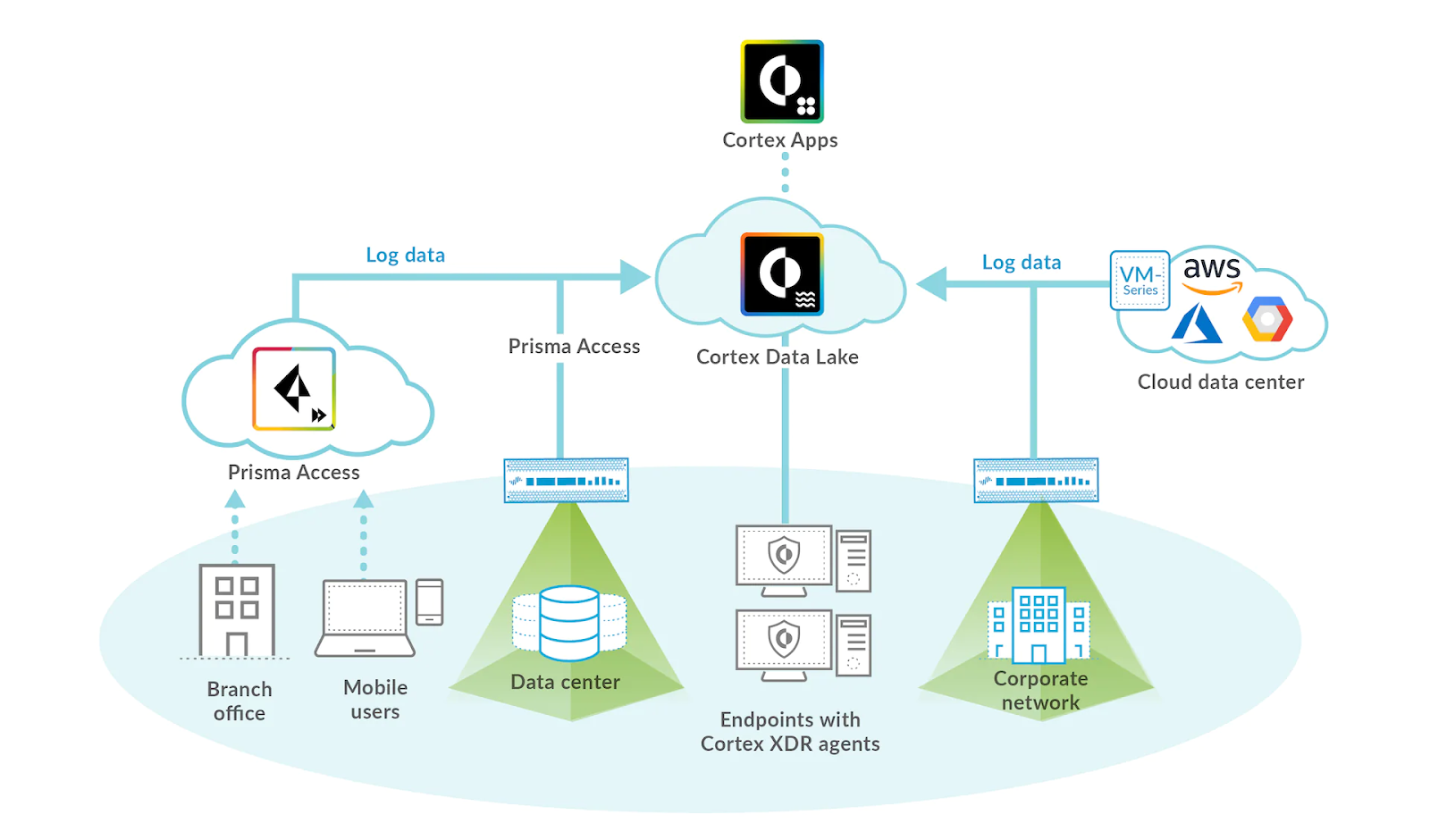
To meet the SLAs, the Cortex Data Lake team had to design a large-scale data infrastructure for real-time processing and reduce time-to-value. One of their initial architectural decisions was to leverage Apache Beam, the industry standard for unified distributed processing, due to its portability and abstraction.
Beam is very flexible, its abstraction from implementation details of distributed data processing is wonderful for delivering proofs of concept really fast.
Apache Beam provides a variety of runners, offering freedom of choice between different data processing engines. Palo Alto Networks’ data infrastructure is hosted entirely on Google Cloud Platform, and with Apache Beam Dataflow runner, we could easily benefit from Google Cloud Dataflow’s managed service and autotuning capabilities. Apache Kafka was selected as the message broker for the backend, and all events were stored as binary data with a common schema on multiple Kafka clusters.
The Cortex Data Lake team considered the option of having separate data processing infrastructures for each customer, with multiple upstream applications creating their own streaming jobs, consuming and processing events from Kafka directly. Therefore we are building a multi-tenants system. However, the team anticipated possible issues related to Kafka migrations and partition creation, as well as a lack of visibility into the tenant use cases, which might arise when having multiple infrastructures.
Hence, the Cortex Data Lake team took a common streaming infrastructure approach. At the core of the common data infrastructure, Apache Beam served as a unified programming model to implement business logic just once for all internal and customer tenant applications.
The first data workflows that the Cortex Data Lake team implemented were simple: reading from Kafka, creating a batch job, and writing the results to sink. The release of the Apache Beam version with SQL support opened up new possibilities. Beam Calcite SQL provides full support for complex Apache Calcite data types, including nested rows, in SQL statements, so developers can use SQL queries in an Apache Beam pipeline for composite transforms. The Cortex Data Lake team decided to take advantage of the Beam SQL to write Beam pipelines with standard SQL statements.
The main challenge of the common infrastructure was to support a variety of business logic customizations and user-defined functions and transform them to a variety of sink formats. Tenant applications needed to consume data from dynamically-changing Kafka clusters, and streaming pipeline DAGs had to be regenerated if the jobs’ source had been updated.
The Cortex Data Lake team developed their own “subscription” model that allows tenant applications to “subscribe” to the streaming job when sending job deployment requests to the REST API service. The Subscription service abstracts tenant applications from the changes in DAG by storing infrastructure-specific information in metadata service. This way, the streaming jobs stay in sync with the dynamic Kafka infrastructure.
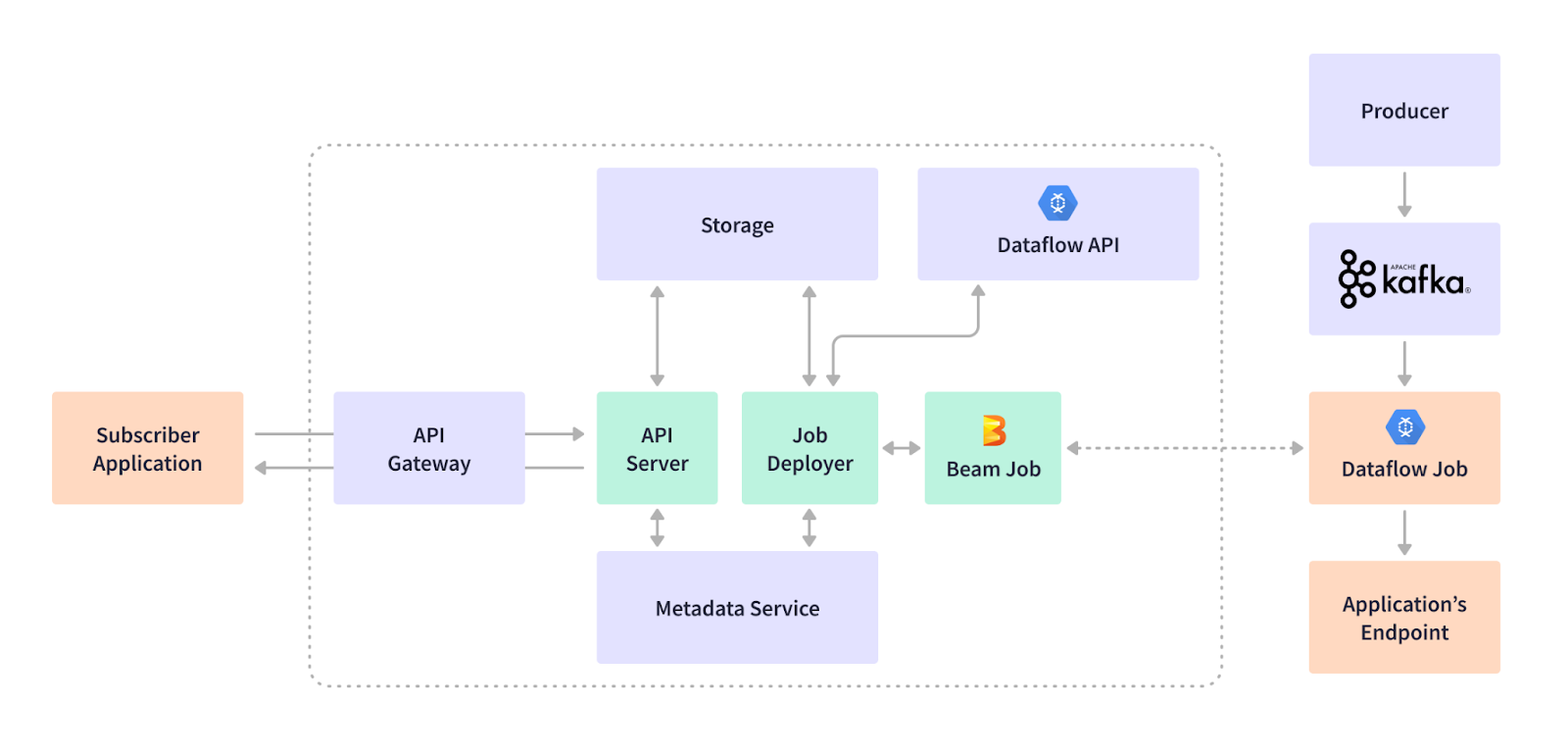
Apache Beam is flexible, it allows creating streaming jobs dynamically, on the fly. The Apache Beam constructs allow for generic pipeline coding, enabling pipelines that process data even if schemas are not fully defined in advance. Cortex’s Subscription Service generates Apache Beam pipeline DAG based on the tenant application’s REST payload and submits the job to the runner. When the job is running, Apache Beam SDK’s Kafka I/O returns an unbounded collection of Kafka records as a PCollection . Apache Avro turns the binary Kafka representation into generic records, which are further converted to the Apache Beam Row format. The Row structure supports primitives, byte arrays, and containers, and allows organizing values in the same order as the schema definition.
Apache Beam’s cross-language transforms allow the Cortex Data Lake team to execute SQL with Java. The output of an SQL Transform performed inside the Apache Beam pipeline is sequentially converted from Beam Row format to a generic record, then to the output format required by a subscriber application, such as Avro, JSON, CSV, etc.
Once the base use cases had been implemented, the Cortex Data Lake team turned to more complex transformations, such as filtering a subset of events directly inside Apache Beam pipelines, and kept looking into customization and optimization.
We have more than 10 use cases running across customers and apps. More are coming, like the machine learning use cases .... for these use cases, Beam provides a really good programming model.
Apache Beam provides a pluggable data processing model that seamlessly integrates with various tools and technologies, which allowed the Cortex Data Lake team to customize their data processing to performance requirements and specific use cases.
Customizing Serialization for Use Cases
Palo Alto Networks’ streaming data infrastructure deals with hundreds of billions of real-time security events every day, and even a sub-second difference in processing times is crucial.
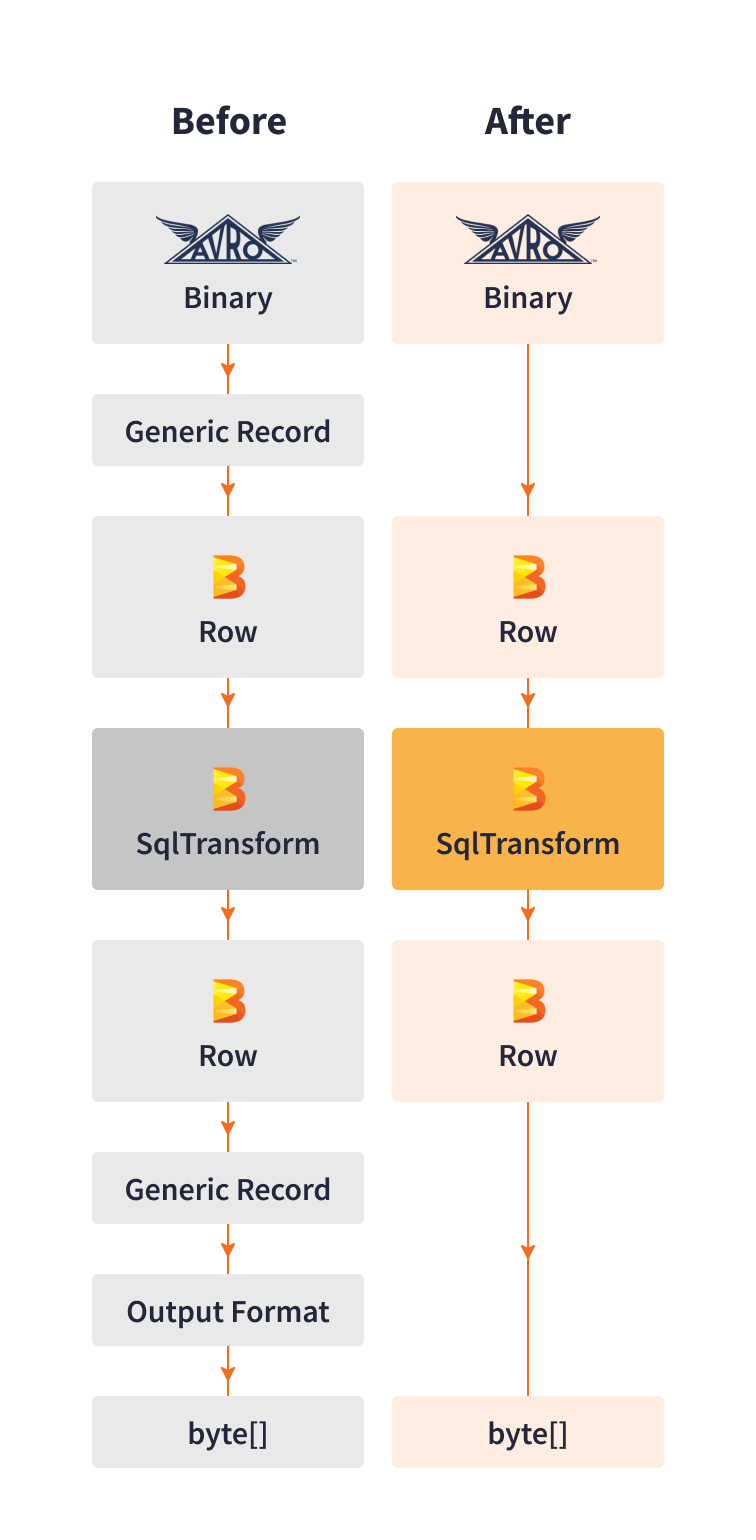
To enhance performance, the Cortex Data Lake team developed their own library for direct serialization and deserialization. The library reads Avro binary records from Kafka and turns them into the Beam Row format, then converts the Beam Row format pipeline output to the required sink format.
This custom library replaced serializing data into generic records with steps optimized for Palo Alto Networks’ specific use cases. Direct serialization eliminated shuffling and creating additional memory copies from processing steps.
This customization increased serialization performance 10x times, allowing to process up to 3K events per second per vCPU with reduced latency and infrastructure costs.
In-flight Streaming Job Updates
At a scale of thousands of jobs running concurrently, the Cortex Data Lake team faced cases when needed to improve the pipeline code or fix bugs for an ongoing job. Google Cloud Dataflow provides a way to replace an “in-flight” streaming job with a new job that runs an updated Apache Beam pipeline code. However, Palo Alto Networks needed to expand the supported scenarios.
To address updating jobs in the dynamically-changing Kafka infrastructure, the Cortex Data Lake team created an additional workflow in their deployment service which drains the jobs if the change is not permitted by the Dataflow update and starts a new job with the exact same naming. This internal job replacement workflow allows the Cortex Data Lake to update the jobs and payloads automatically for all use cases.
Handling Schema Changes In Beam SQL
Another use case that Palo Alto Networks tackled is handling changes in data schemas for ongoing jobs. Apache Beam allows PCollections to have schemas with named fields, that are validated at pipeline construction step. When a job is submitted, an execution plan in the form of a Beam pipeline fragment is generated based on the latest schema. Beam SQL does not yet have built-in support for relaxed schema compatibility for running jobs. For optimized performance, Beam SQL’s Schema RowCoder has a fixed data format and doesn’t handle schema evolution, so it is necessary to restart the jobs to regenerate their execution plan. At a scale of 10K+ streaming jobs, Cortex Data Lake team wanted to avoid resubmitting the jobs as much as possible.
We created an internal workflow to identify the jobs with SQL queries relevant to the schema change. The schema update workflow stores Reader schema of each job (Avro schema) and Writer schema of each Kafka message (metadata on Kafka header) in the internal Schema Registry, compares them to the SQL queries of the running jobs, and restarts the affected jobs only. This optimization allowed them to utilize resources more efficiently.
Fine-tuning Performance for Kafka Changes
With multiple clusters and topics, and over 100K partitions in Kafka, Palo Alto Networks needed to make sure that actively-running jobs are not being affected by the frequent Kafka infrastructure changes such as cluster migrations or changes in partition count.
The Cortex Data Lake team developed several internal Kafka lifecycle support tools, including a “Self Healing” service. Depending on the amount of traffic per topic coming from a specific tenant, the internal service increases the number of partitions or creates new topics with fewer partitions. The “Self Healing” service compares the Kafka states in the data store and then finds and updates all related streaming Apache Beam jobs on Cloud Dataflow automatically.
With the release of Apache Beam 2.28.0 in early 2021, the pre-built Kafka I/O dynamic read feature provides an out-of-the-box solution for detecting Kafka partition changes to enable cost savings and increased performance. Kafka I/O uses WatchKafkaTopicPartitionDoFn to emit new TopicPartitions, and allows reading from Kafka topics dynamically when certain partitions are added or stop reading from them once they are deleted. This feature eliminated the need to create in-house Kafka monitoring tools.
In addition to performance optimization, the Cortex Data Lake team has been exploring ways to optimize the Cloud Dataflow costs. We looked into resource usage optimization in cases when streaming jobs consume very few incoming events. For cost efficiency, Google Cloud Dataflow provides the streaming autoscaling feature that adaptively changes the number of workers in response to changes in the load and resource utilization. For some of Cortex Data Lake team’s use cases, where input data streams may quiesce for prolonged periods of time, we implemented an internal “Cold Starter” service that analyzes Kafka topics traffic and hibernates pipelines whose input dries up and reactivates them once their input resumes.
Talat Uyarer presented the Cortex Data Lake’s experience of building and customizing the large-scale streaming infrastructure during Beam Summit 2021.
I really enjoy working with Beam. If you understand its internals, the understanding empowers you to fine-tune the open source, customize it, so that it provides the best performance for your specific use case.
Results
The level of abstraction of Apache Beam empowered the Cortex Data Lake team to create a common infrastructure across their internal apps and tens of thousands of customers. With Apache Beam, we implement business logic just once and dynamically generate 10K+ streaming pipelines running in parallel for over 10 use cases.
The Cortex Data Lake team took advantage of Apache Beam’s portability and pluggability to fine-tune and enhance their data processing infrastructure with custom libraries and services. Palo Alto Networks ultimately achieved high performance and low latency, processing 3K+ streaming events per second per vCPU. Combining the benefits of open source Apache Beam and Cloud Dataflow managed service, we were able to implement use-case specific customizations and reduced their costs by more than 60%.
The Apache Beam open source community welcomes and encourages the contributions of its numerous members, such as Palo Alto Networks, that leverage the powerful capabilities of Apache Beam, bring new optimizations, and empower future innovation by sharing their expertise and actively participating in the community.
Was this information useful?