




“Apache Beam is a well-defined data processing model that lets you concentrate on business logic rather than low-level details of distributed processing.”

Scalability and Cost Optimization for Search Engine’s Workloads
Background
Seznam.cz is a Czech search engine that serves over 25% of local organic search traffic. Seznam employs over 1,500 people and runs a portfolio of more than 30 web services and associated brands, processing around 15 million queries a day.
Seznam continuously optimizes their big data infrastructure, web crawlers, algorithms, and ML models on a mission to achieve excellence in accuracy, quality, and usefulness of search results for their users. Seznam has been an early contributor and adopter of Apache Beam, and they migrated several petabyte-scale workloads to Apache Beam pipelines running in Apache Spark and Apache Flink clusters in Seznam’s on-premises data center.
Journey to Apache Beam
Seznam started using MapReduce in a Hadoop Yarn cluster back in 2010 to facilitate concurrent batch jobs processing for the web crawler components of their search engine. Within several years, their data infrastructure evolved to over 40 billion rows with 400 terabytes in HBase, 2 on-premises data centers with over 1,100 bare metal servers, 13 PB storage, and 50 TB memory, which made their business logic more complex. MapReduce no longer provided enough flexibility, cost efficiency, and performance to support this growth, and Seznam rewrote the jobs to native Spark. Spark shuffle operations enabled Seznam to split large data keys into partitions, load them in-memory one by one, and process them iteratively. However, exponential data skews and inability to fit all values for a single key into an in-memory buffer resulted in increased disk space utilization and memory overhead. Some tasks took unexpectedly long time to complete, and it was challenging to debug Spark pipelines due to generic exceptions. Thus, Seznam needed a data processing framework that can scale more efficiently.
To manage this kind of scale, you need the abstraction.
In 2014, Seznam started work on Euphoria API - a proprietary programming model that can express business logic in batch and streaming pipelines and allow for runner independent implementation.
Apache Beam was released in 2016 and became a readily available and well-defined unified programming model. This engine-independent model has been evolving very fast, supports multiple shuffle operators and fits perfectly into Seznam’s existing on-premises data infrastructure. For a while, Seznam continued to develop Euphoria, but soon the high cost and the amount of effort needed to maintain the solution and create their own runners in-house surpassed the benefits of having a proprietary framework.

Seznam started migrating their key workloads to Apache Beam. They decided to merge the Euphoria API as a high-level DSL for Apache Beam Java SDK. This significant contribution to Apache Beam was a starting point for Seznam’s active participation in the community, later presenting their unique experience and findings at Beam Summit Europe 2019 and developer conferences.
Adopting Apache Beam
Apache Beam enabled Seznam to execute batch and stream jobs much faster without increasing memory and disk space, thus maximizing scalability, performance, and efficiency.
Apache Beam offers a variety of ways to distribute skewed data evenly. Windowing for processing unbounded and Partition for bounded data sets transform input into finite collections of elements that can be reshuffled. Apache Beam provides a byte-based shuffle that can be executed by Spark runner or Flink runner, without requiring Apache Spark or Apache Flink to deserialize the full key. Apache Beam SDKs provide effective coders to serialize and deserialize elements and pass to distributed workers. Using Apache Beam serialization and byte-based shuffle resulted in substantial performance gains for many of the Seznam’s use cases and reduced memory required for the shuffling by Apache Spark execution environment. Seznam’s infrastructure costs associated with disk I/O and memory splits decreased significantly.
One of the most valuable use cases is Seznam’s LinkRevert job, which analyzes the web graph to improve search relevance. This data pipeline figuratively “turns the Internet upside down”, processing over 150 TB daily, extending redirect chains to identify every successor of a specific URL, and discovering backlinks that point to a specific web page. The Apache Beam pipeline executes multiple large-scale skewed joins, and scores the URLs for search results based on the redirect and backlinking factors.
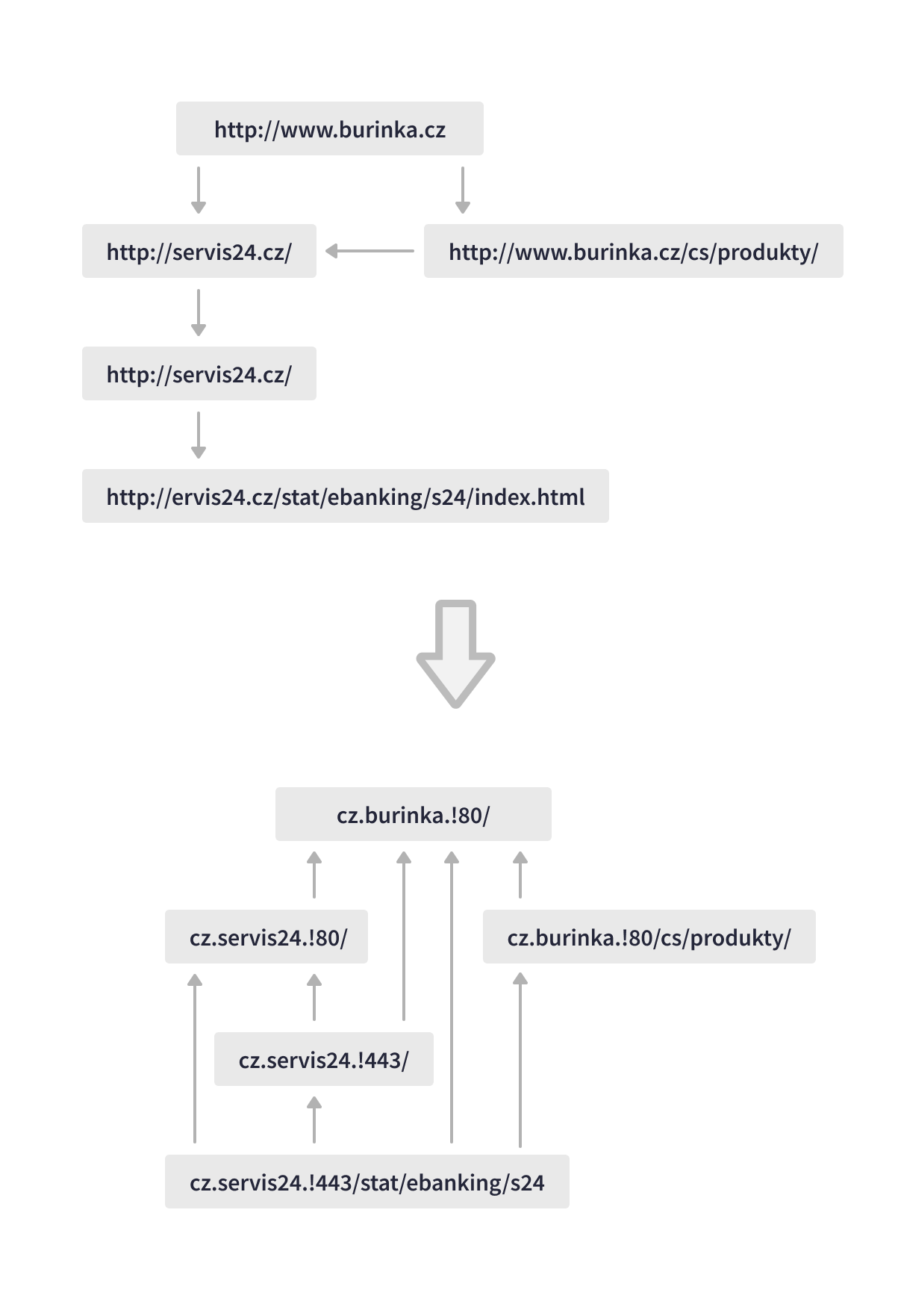
Apache Beam allows for a unified engine-independent execution, so Seznam was able to select between Spark or Flink runner depending on the use case. For example, the Apache Beam batch pipeline executed by Spark runner on a Hadoop Yarn cluster parses new web documents, enriches data with additional features, and scores the web pages based on their relevance, ensuring timely database updates and accurate search results. Apache Beam stream processing runs in the Apache Flink execution environment on a Kubernetes cluster for thumbnail requests that are displayed in users’ search results. Another example of stream event processing is the Apache Beam Flink runner pipeline that maps, joins, and processes search logs to calculate SLO metrics and other features.
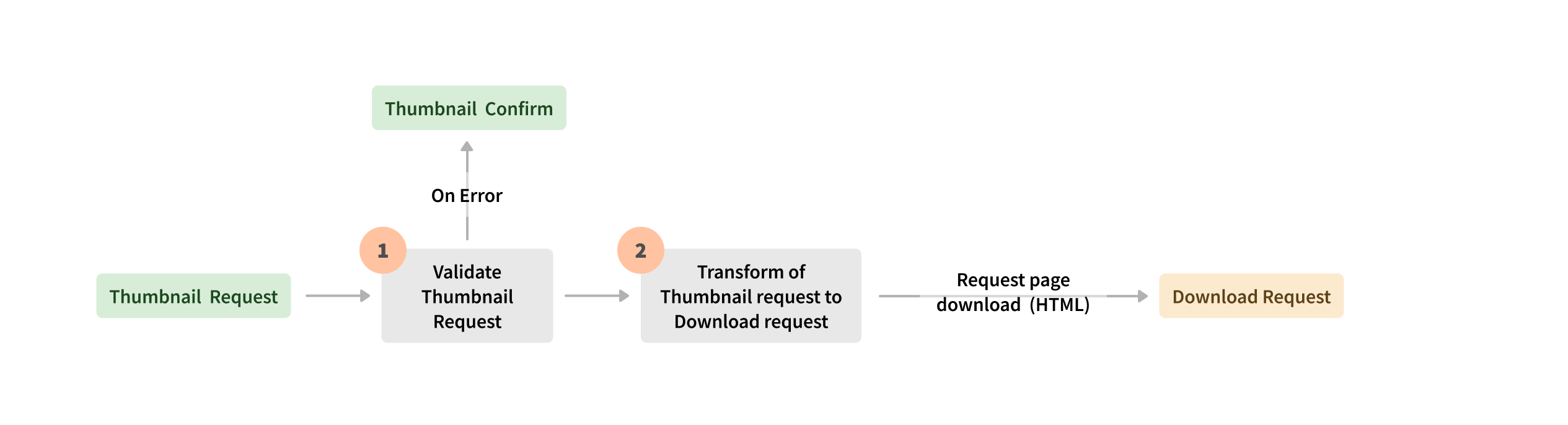
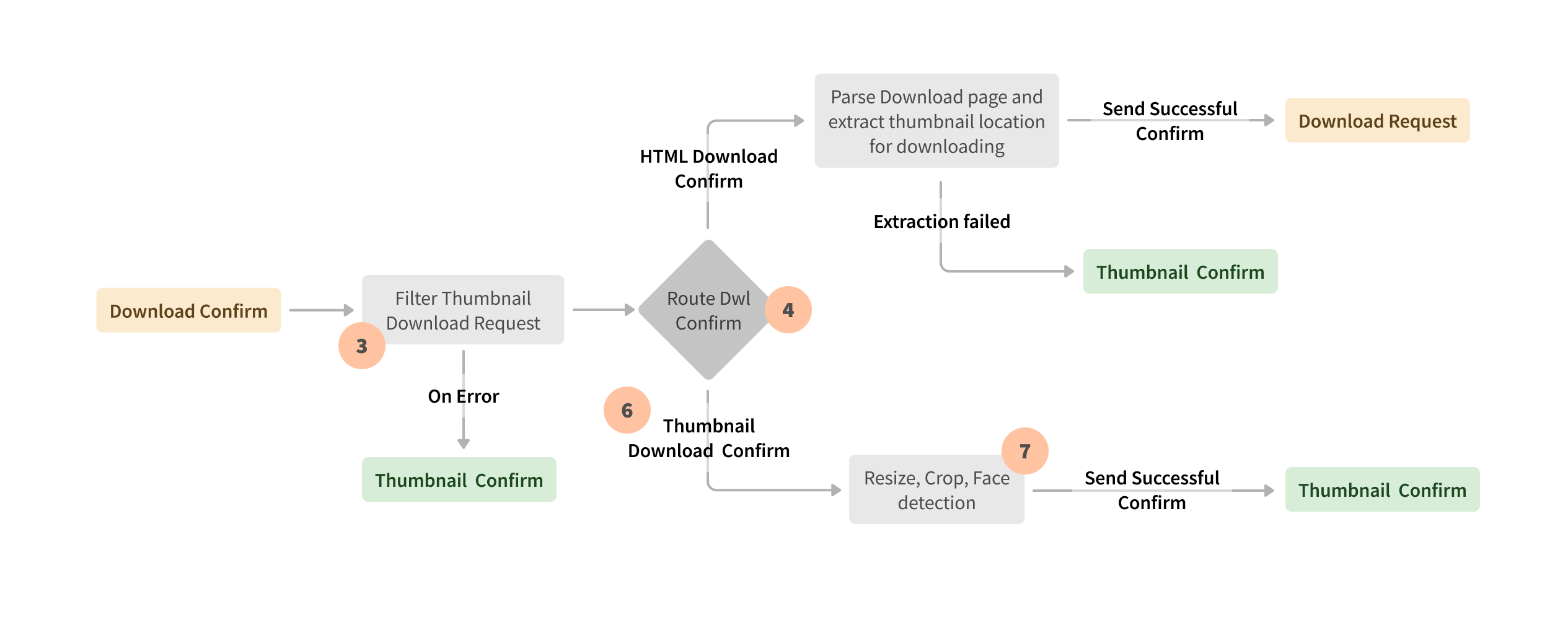
Over the years, Seznam’s approach has evolved. They have realized the tremendous benefits of Apache Beam for balancing petabyte-size workloads and optimizing memory and compute resources in on-premises data centers. Apache Beam is Seznam’s go-to platform for batch and stream pipelines that require multiple shuffle operations, processing skewed data, and implementing complex business logic. Apache Beam unified model with sources and sinks exposed as transforms, increased business logic maintainability and traceability with unit tests.
One of the biggest benefits is Apache Beam sinks and sources. By exposing your source or sink as a transform, your implementation is hidden and later on, you can add additional functionality without breaking the existing implementation for users.
Monitoring and Debugging
Apache Beam pipelines monitoring and debugging was critical for cases with complex business logic and multiple data transformations. Seznam engineers identified optimal tools depending on the execution engine. Seznam leveraged Babar from Criteo to profile Apache Beam pipelines on Spark runner and identify the root causes of downtimes in their performance. Babar allows for easier monitoring, debugging, and performance optimization by analyzing cluster resource utilization, memory allocated, CPU used, etc. For Apache Beam pipelines executed by Flink runner on Kubernetes cluster, Seznam employs Elasticsearch to store, search, and analyze metrics.
Results
Apache Beam offered a unified model for Seznam’s stream and batch processing that provided performance at scale. Apache Beam supported multiple runners, language SDKs, and built-in and custom pluggable I/O transforms, thus eliminating the need to invest into the development and support of proprietary runners and solutions. After evaluation, Seznam transitioned their workloads to Apache Beam and integrated Euphoria API (a fast prototyping framework developed by Seznam), contributing to the Apache Beam open source community.
The Apache Beam abstraction and execution model allowed Seznam to robustly scale their data processing. It also provided the flexibility to write the business logic just once and keep freedom of choice between runners. The model was especially valuable for pipeline maintainability in complex use cases. Apache Beam helped overcome memory and compute resource constraints by reshuffling unevenly distributed data into manageable partitions.
Was this information useful?