



Apache Beam Overview
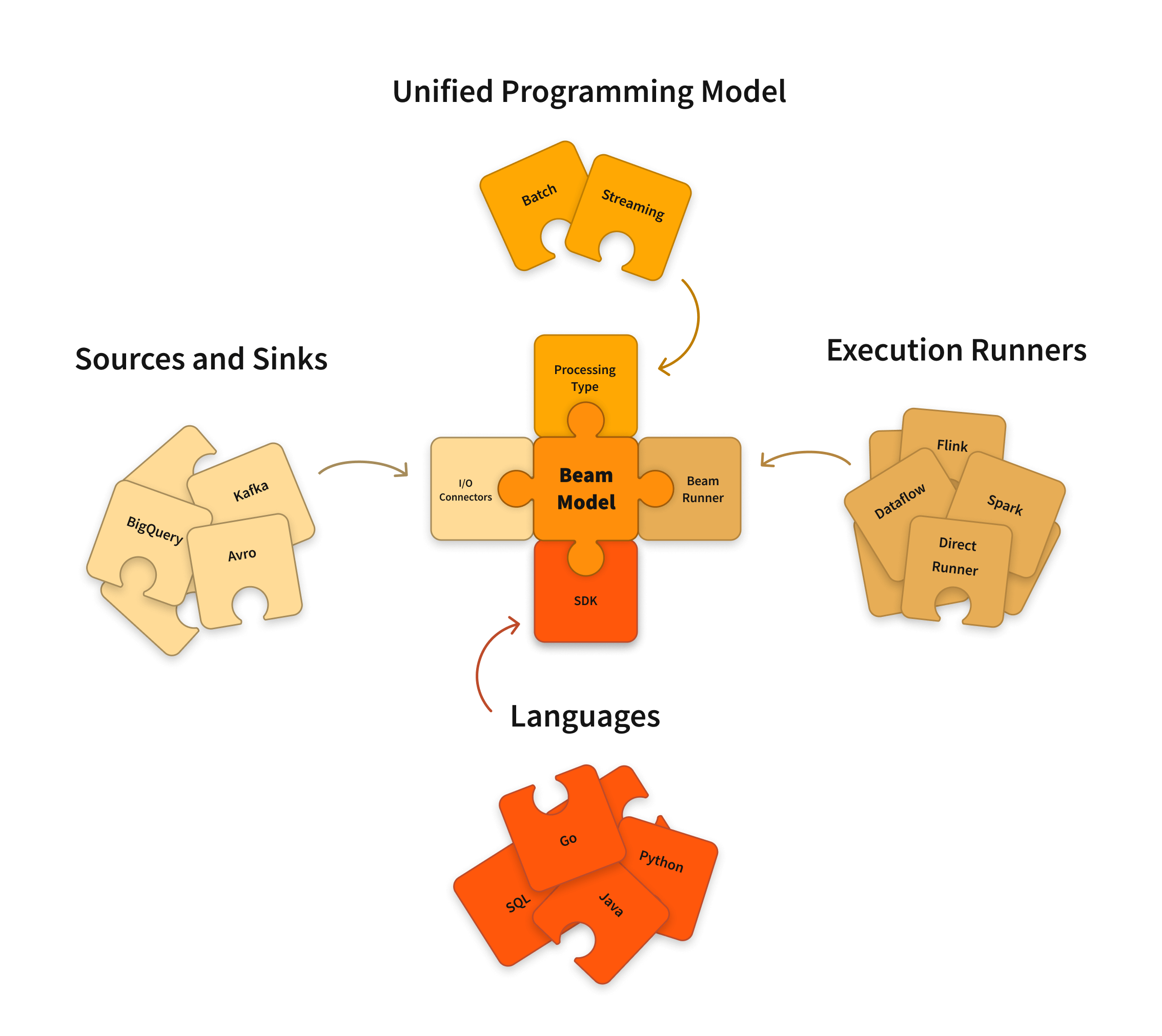
Apache Beam is an open source, unified model for defining both batch and streaming data-parallel processing pipelines. Using one of the open source Beam SDKs, you build a program that defines the pipeline. The pipeline is then executed by one of Beam’s supported distributed processing back-ends, which include Apache Flink, Apache Spark, and Google Cloud Dataflow.
Beam is particularly useful for embarrassingly parallel data processing tasks, in which the problem can be decomposed into many smaller bundles of data that can be processed independently and in parallel. You can also use Beam for Extract, Transform, and Load (ETL) tasks and pure data integration. These tasks are useful for moving data between different storage media and data sources, transforming data into a more desirable format, or loading data onto a new system.
Apache Beam SDKs
The Beam SDKs provide a unified programming model that can represent and transform data sets of any size, whether the input is a finite data set from a batch data source, or an infinite data set from a streaming data source. The Beam SDKs use the same classes to represent both bounded and unbounded data, and the same transforms to operate on that data. You use the Beam SDK of your choice to build a program that defines your data processing pipeline.
Beam currently supports the following language-specific SDKs:



A Scala  interface is also available as Scio.
interface is also available as Scio.
Apache Beam Pipeline Runners
The Beam Pipeline Runners translate the data processing pipeline you define with your Beam program into the API compatible with the distributed processing back-end of your choice. When you run your Beam program, you’ll need to specify an appropriate runner for the back-end where you want to execute your pipeline.
Beam currently supports the following runners:
- Direct Runner
- Apache Flink Runner

- Apache Nemo Runner
- Apache Samza Runner

- Apache Spark Runner

- Google Cloud Dataflow Runner

- Hazelcast Jet Runner

- Twister2 Runner

Note: You can always execute your pipeline locally for testing and debugging purposes.
Get Started
Get started using Beam for your data processing tasks.
If you already know Apache Spark, check our Getting started from Apache Spark page.
Take the Tour of Beam as an online interactive learning experience.
Follow the Quickstart for the Java SDK, the Python SDK, or the Go SDK.
See the WordCount Examples Walkthrough for examples that introduce various features of the SDKs.
Take a self-paced tour through our Learning Resources.
Dive into the Documentation section for in-depth concepts and reference materials for the Beam model, SDKs, and runners.
Dive into the cookbook examples for learning how to run Beam on Dataflow.
Contribute
Beam is an Apache Software Foundation project, available under the Apache v2 license. Beam is an open source community and contributions are greatly appreciated! If you’d like to contribute, please see the Contribute section.
Last updated on 2026/04/28
Have you found everything you were looking for?
Was it all useful and clear? Is there anything that you would like to change? Let us know!